Enterprises are putting AI to work on their own data: analyzing contracts and filings, reviewing recorded calls and meetings, working through case files and footage to reach an answer faster than a person could. The capability is real. The open question is whether the answer that comes back will hold up when someone asks you to back it up.
That someone might be a regulator, a court, an internal auditor, a customer, or your own risk committee. An answer your AI reached by analyzing your data is only useful if you can show where it came from, and an answer that merely sounds right is not the same as one you can defend.
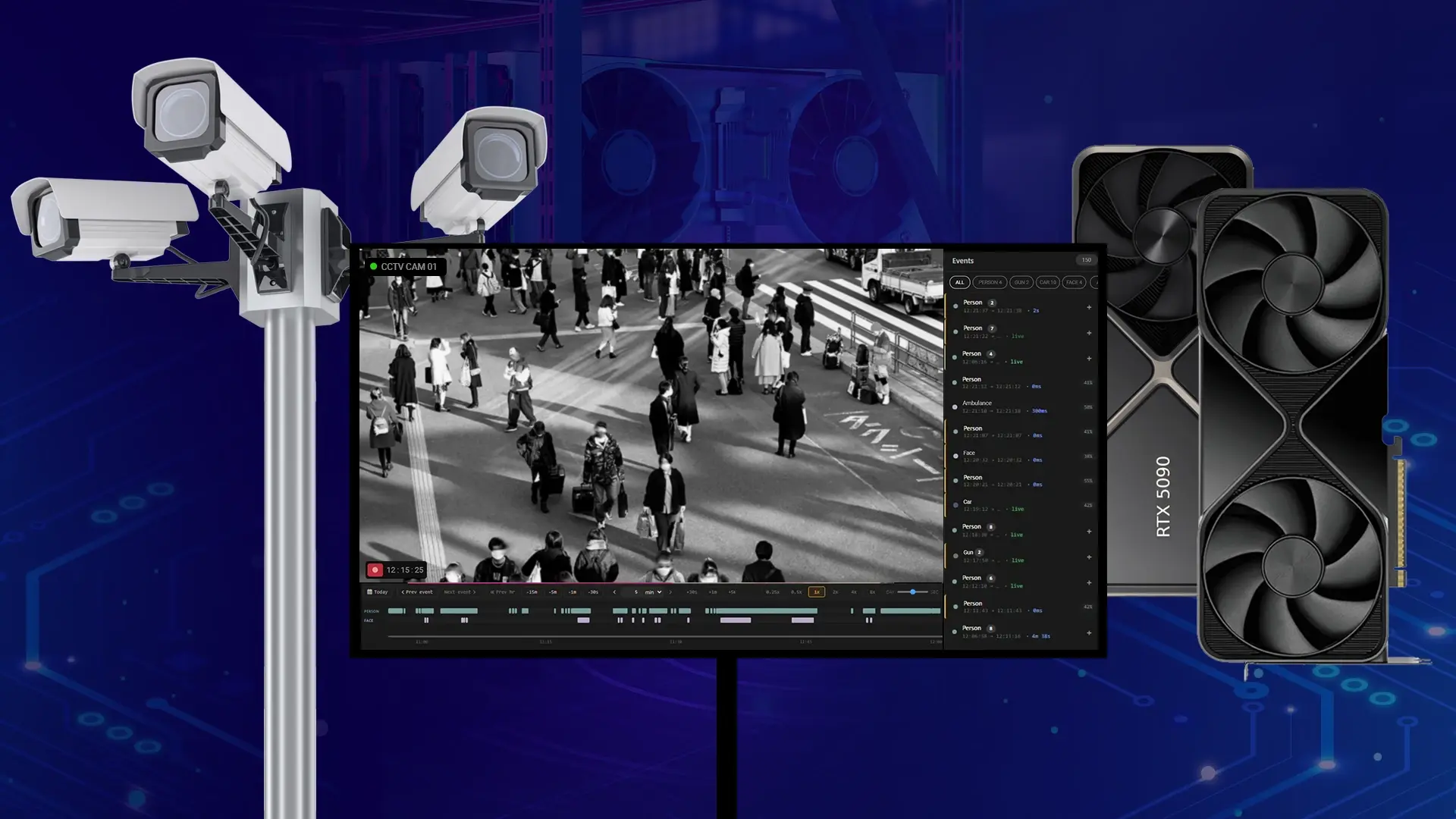
This is where sourced analysis matters. When AI analyzes your material, the answer should arrive with its evidence attached: the document and page, the moment in a recording, a confidence score, and the reviewer who signed off. That is what makes AI analysis audit-ready, and it is the line between a tool you can use on real work and one that stays in a sandbox.
Compliance teams hit this first, because they answer to examiners. But legal, risk, security, and any function whose decisions carry weight face the same test. This guide covers what makes analyzed answers defensible, why unsourced analysis fails, the questions you will be asked, how a sourced answer is produced, and where a human still signs.
What Makes AI Analysis Defensible?
Defensible AI analysis is analysis whose every answer can be traced back to the data it came from, reproduced, and stood behind. When AI works through your documents and recordings to answer a question, the result is not just a sentence. It is an answer plus the evidence the system used to reach it.
The shift is from trusting the model to verifying its work. You do not have to believe the analysis is right. You have to be able to open the source it points to and check, and to show that source to someone paid to be skeptical.
An answer that can do that is audit-ready. One that cannot, however fluent, is a liability the moment it informs a real decision.
Reasoning Trace vs Why-Trail: What a Defensible Answer Carries
There is a meaningful difference between two things an AI system can show you about an answer.
A reasoning trace is the model narrating how it thinks. It looks convincing in a demo and helps with debugging. It is also prose generated by the same system whose output you are checking, which means it is not evidence.
A why-trail is the record of what the analysis actually used, and anyone can verify it independently. For each answer it captures the source documents retrieved with their page or timestamp, the passages the model drew on, a confidence score and the threshold that allowed or held the answer, the rule or policy applied, the reviewer who approved it, and the result.
A reasoning trace tells you what the model said it did. A why-trail shows what the analysis actually did, in a form an auditor or opposing counsel can pull and inspect. In practice a sourced answer looks less like a sentence and more like this:
Answer: The certificate meets the minimum coverage requirement. Source: Certificate of Insurance, page 3, field "General Aggregate Limit," value 2,100,000. Confidence: 98.7 percent. Rule applied: Policy 4.2, minimum aggregate coverage 2,000,000. Result: Pass. Reviewed and approved by a named reviewer, with date.
Every element is independently checkable. An examiner can open the certificate, confirm the value, check the rule version, and see who approved it, without taking the model's word for any of it.
Why Unsourced AI Analysis Doesn't Hold Up
The audiences that question an AI-assisted decision do not accept "the system said so." An answer produced by analyzing your data has to satisfy three independent tests.
Provenance asks where the underlying facts came from and whether those sources are approved for the use. Reproducibility asks whether the same question over the same material returns the same answer or a defensible variant. Accountability asks who saw the answer, what they did with it, and whether they were qualified to.
A black-box chatbot fails all three, and the failure is not hypothetical. In one Stanford study, general-purpose models invented legal citations in 69 to 88 percent of queries about federal court cases, the kind of confident fabrication that flows straight into a filing if nothing catches it.
The defense is not a better model but a retrieval-grounded architecture that cites its sources and routes flagged answers through human review. The model analyzes. The architecture around it is what makes the answer one you can defend.
What Regulators, Courts, and Auditors Actually Ask
Most enterprise AI tools log prompts and responses. That is not the same as a record of the analysis, and the gap shows the moment someone with authority starts asking questions. Whether the questioner is a financial examiner, a judge, an internal auditor, or a customer's counsel, the questions sound like this:
- For this answer produced on a given date, which version of the source document did the analysis use?
- Why was confidence high enough to release this answer without human review?
- Show every answer the system produced about this customer or matter, including the ones held back as low-confidence.
- When the underlying policy or regulation changed, which prior answers were flagged for re-review?
- Who is the named reviewer for this decision, and were they working from the current version of the workflow?
A prompt-and-response log cannot answer any of these. A why-trail answers all of them in a single query, because the evidence is captured as the analysis runs rather than reconstructed under pressure later.
How AI Analysis Produces a Sourced Answer
A sourced answer is not something you bolt onto analysis afterward. It is captured as the system works through your data, so the evidence is part of the answer rather than a reconstruction you attempt later.
As the system retrieves, it records which documents it pulled into context, their version, and the passages used, so an answer always points to the material that existed at the time. As it generates the answer, it stores the grounding passages, the prompt version, and the model used, so you can later tell exactly what produced the result and on what data.
At the confidence gate, the score and the threshold that released or held the answer are recorded, so a reviewer can see why it went straight through or stopped for a person. At review, the reviewer's identity, decision, and any edits become part of the answer. At delivery, the version handed over is timestamped and held, so a later dispute is settled against the exact answer and its evidence.
Because the trail is produced as the analysis runs, a records request that used to take days becomes a single query, the same shift purpose-built systems already deliver for managing audit evidence at scale. You pull the answer and its evidence together, not a transcript to interpret.
The Rules Driving Defensible AI: NYDFS, the Courts, and the EU AI Act
Regulators and courts have started writing this expectation down, and not only in financial services. New York's Department of Financial Services issued an industry letter on cybersecurity risks arising from artificial intelligence that treats AI-assisted decisions as a risk to be governed, monitored, and documented, with the practical implications for running AI on infrastructure you control following directly from it.
The courts have gone further. A May 2026 federal ruling held that an organization could not escape liability for AI-assisted decisions by blaming the tool, and a reading of three federal decisions together points to a consistent standard: defensible AI use requires confidential infrastructure, human direction, and a documentable record. Beyond the United States, the EU AI Act assigns explicit logging and human-oversight obligations to high-risk systems.
The thread through all of it is the same regardless of industry. AI used in a consequential decision needs documented analysis, named human accountability, and evidence that the controls operated as designed.
The Federal Reserve's SR 11-7 model risk management framework, written for credit and trading models, is increasingly treated as the baseline for generative AI in regulated firms for the same reason. Courts have now begun defining what sufficient human oversight actually looks like, and analysis that returns sourced answers with a why-trail is how an enterprise meets that bar in practice rather than on paper.
Where Human Review Still Signs Off
A common misreading is that sourced analysis removes the human reviewer. It does not, and regulators are explicit that it should not.
The reviewer's role shifts from doing the lookup to checking the analysis. They calibrate the confidence threshold and defend where it is set, review the answers that route to a person because they are low-confidence or touch a sensitive subject, sample answers that passed automatically to confirm the gate is set right, and periodically attest that the workflow ran as documented.
This is the pattern legal teams describe as keeping AI in the research seat and a qualified person in the decision seat. The system handles the volume of analysis. The person handles judgment, exceptions, and the signature on the decision.
How Defensible AI Analysis Plays Out Across the Enterprise
The same need shows up wherever AI analyzes data that matters.
A financial compliance team analyzing filings and recorded calls for an examiner needs every answer tied to its source, the workload that AI document analysis for financial services is built around. A legal team analyzing a case file has to prove that an attorney, not a model, made every substantive call.
A government agency analyzing grant applications or records requests has to document the human oversight behind a decision, the precise failure the SDNY ruling punished. A security team analyzing flagged activity needs each conclusion tied to the evidence that triggered it.
In every case the requirement is the same: an answer with a source, a confidence level, and a reviewer attached.
How VIDIZMO Intelligence Hub Delivers Sourced Analysis
VIDIZMO Intelligence Hub is built to analyze your data and return answers you can defend. It works across video, audio, documents, and images together, and every answer it produces carries the sources it used, the passages behind them, and a confidence score, with no black-box output.
Human-in-the-loop checkpoints can sit at any point in the analysis, with thresholds set per use case and per data sensitivity, and the system records reviewer identity, decisions, and overrides against the original answer. The why-trail is a product of how it analyzes, not a separate logging tool bolted on beside it.
Because regulated data cannot leave the building, the platform analyzes on-premises, in a private cloud, or fully air-gapped, so source material and the answers drawn from it stay inside the environment you control. Model and embedding choices are configurable per workflow, for when someone asks why a particular model produced a particular answer. This is the same design behind its sourced, explainable answers across every format.
Run your own material through it and see the sourced answers it produces: book a demo.