by Nadeem Khan, Last updated: June 4, 2026

A single commercial dispute can produce hundreds of thousands of pages in discovery. A patent case adds claim charts, prior art references, and inventor notebooks on top of that. A government investigation adds bodycam footage, interview recordings, and scanned records going back decades. The documents are only part of it: modern case files mix text, audio, video, and images, and the deadlines attached to them don't bend.
Legal document processing is the workflow that turns that raw material into something a legal team can actually use. It covers ingestion, OCR, classification, search, translation, summarization, and review routing across the full case lifecycle. Done well, it means counsel spends time on strategy and argument instead of reading.
Done poorly (the default state at most organizations), it means review costs that scale linearly with volume, missed documents that surface at the worst possible moment, and work product nobody can reconstruct when a court asks how an answer was produced. This guide gives legal operations leads, litigation support directors, and the CIOs who support them a framework for evaluating AI document processing, with patent litigation, the hardest document workload in law, as the working example throughout.
Key Takeaways
- Legal document processing spans ingestion, OCR, classification, semantic search, translation, and review workflows across documents, audio, video, and images, not text alone.
- The highest-value AI tasks are first-pass review and triage, cited question-answering across the case file, multilingual processing, and deposition and recording analysis, not blanket automation.
- Patent litigation is the stress test: structured claim language, dense citations, multilingual prior art, and extreme confidentiality requirements break generic document AI fastest.
- Confidentiality and deployment control disqualify most cloud-only AI tools before evaluation begins. Privileged material and draft work product need on-premises or air-gapped options.
- Defensibility is the deciding criterion. Every AI output needs source citations, audit trails, and human review checkpoints, because legal work product ends up in front of judges.
What Is Legal Document Processing in Plain Terms?
Legal document processing is the structured handling of case-related content across its lifecycle: discovery productions, contracts, pleadings, deposition transcripts and video, expert reports, investigation records, and the correspondence around all of it. The work spans three layers. The ingestion layer covers OCR, format normalization, and metadata extraction across whatever arrives, from native files to scanned paper to recorded media.
The understanding layer covers classification, entity and PII detection, transcription of audio and video, and indexing for search. The workflow layer covers review routing, human-in-the-loop checkpoints, annotation, and integration with the document management and review platforms a team already runs, mapping roughly to the processing, review, and analysis stages of the EDRM framework.
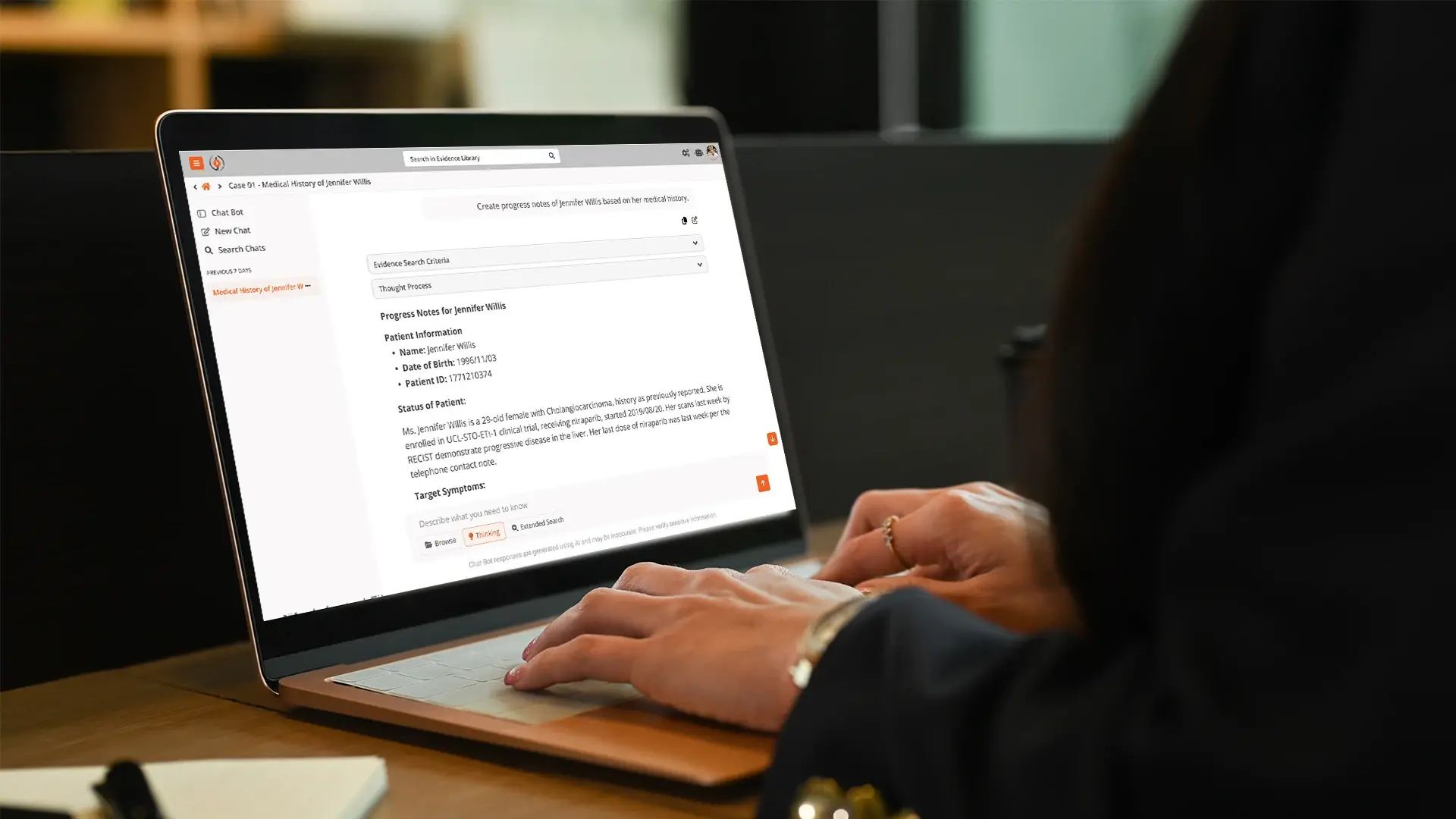
Legal documents differ from ordinary corporate documents in ways that matter for AI. They carry privilege and confidentiality obligations that constrain where they can be processed. They demand provenance: an answer without a traceable source is a liability, not a convenience. And increasingly they aren't documents at all. Deposition video, custodian interviews, and surveillance footage carry evidence that text-only tools like the current wave of legal AI assistants never see, a gap we cover in depth in our guide to AI legal evidence analysis.
Why Have Litigation Document Volumes Become Unmanageable?
Three forces compound each other. Discovery productions keep growing because the underlying business data keeps growing; email, chat, and collaboration platforms generate more potentially responsive material every year.
Review budgets don't grow to match, which pushes teams toward sampling and keyword culling that miss documents semantic search would catch, even though the proportionality standard under FRCP Rule 26 doesn't excuse missing what a reasonable search would have found. And the modality mix keeps shifting: a case file that was 95 percent text a decade ago now routinely includes hours of recorded depositions, hearings, and interviews that someone has to watch, or that nobody does.
The teams feeling this most acutely are the ones handling matters where the documents themselves are technical. Patent litigation sits at the extreme end, which is why it makes a useful stress test for any platform claiming to handle legal documents.
Why Is Patent Litigation the Hardest Legal Document Workload?
Patent disputes concentrate every difficulty in legal document processing into one matter, against a backdrop of relentless volume growth: WIPO recorded 3.7 million patent applications globally in 2024, the highest on record, and the USPTO's backlog of unexamined applications peaked at 837,928 in January 2025. Every one of those filings is a potential reference in someone's future case. Four characteristics make the resulting document work brutal.
Structured technical language
Patent claims follow a strict hierarchy built on transitional phrases ("comprising," "consisting of") that carry binding legal meaning. Finding every document and deposition moment where a specific claim limitation is discussed requires search that understands the concept, not just the keyword.
Mixed modalities
Drawings are referenced by numbered elements throughout a specification, and their interpretation is part of claim construction. Inventor testimony lives on video. Lab notebooks arrive as scans. A text-only tool loses the connections between them.
Multilingual prior art
A serious invalidity analysis pulls Japanese, Chinese, Korean, and German references. Translation quality directly affects whether a reference is correctly evaluated, and in our experience machine translation gaps in Chinese and Japanese prior art are among the most consistent sources of missed references.
Extreme confidentiality
Draft applications, freedom-to-operate analyses, and litigation strategy documents are among the most sensitive material an organization owns. Processing them through a cloud tool the legal team doesn't control can be a confidentiality breach in itself.
A platform that handles patent litigation handles everything below it. That's the logic of using it as the evaluation benchmark even if your docket is mostly commercial disputes or government matters.
Which Legal Document Tasks Benefit Most From AI?
Not every task in the legal workflow needs AI, and the highest legal stakes belong with counsel. Five tasks consistently deliver the most value.
First-pass review and triage
Classification, deduplication, and relevance scoring across a production set shrink the volume that reaches human reviewers. AI moves the bottleneck from reading to validating, which is a much better bottleneck to have.
Cited question-answering across the case file
Retrieval-augmented generation over the full corpus lets a team ask "where is the damages methodology discussed?" and get an answer with pinpoint citations to the source page or the timestamp in a recording. The citation is the point: an uncited answer has no place in legal work.
Multilingual processing
Machine translation and multilingual OCR now produce searchable, reviewable output for the major commercial languages, which means foreign-language documents get reviewed instead of budgeted out of the case.
Deposition and recording analysis
Transcription, speaker attribution, and semantic search over audio and video turn recorded testimony into a searchable asset. Finding the three minutes where a witness contradicts an exhibit stops being an associate's weekend.
Summarization and chronology building
Drafting first-pass summaries, timelines, and witness binders from source material gives the team a starting point that's hours old instead of weeks old. Counsel still verifies everything against the cited sources.
What doesn't belong on this list is legal judgment: privilege calls (where Federal Rule of Evidence 502 makes "reasonable steps to prevent disclosure" the standard for avoiding waiver), final work product, opinions, and strategy. We have seen teams get burned by treating AI drafts as finished product. The defensible workflow puts AI in the research and synthesis seat and keeps a qualified human in the decision seat.
How Should Legal Teams Evaluate AI Document Processing Tools?
Most tools demo well on a curated document set and break on a real production. Five checks separate serious candidates from polished demos. Run the evaluation on your own corpus, including the scanned, skewed, and handwritten material a real matter contains, not the vendor's sample set.
Test the modalities you actually have: if depositions and recordings are part of your case files, a text-only tool fails the evaluation by definition. Get confidentiality controls in the contract, not the marketing copy: where the data is processed, whether the vendor trains on it, and what deployment options exist for privileged material. Demand explainability, meaning every answer traceable to a source page or timestamp. And evaluate integration honestly, because a platform that doesn't connect to your existing document management and review stack adds steps instead of removing them.
Common Pitfalls When Legal Teams Adopt AI Document Workflows
The most common mistake is starting with drafting. AI-drafted briefs and opinions need so much attorney editing that the cycle often takes longer than starting clean. Review triage, search, transcription, and translation are better starting points because the output is verifiable against sources.
Teams also underestimate validation. AI shifts effort from reading to checking, and checking needs to be planned, staffed, and quality-tracked like any other review stage. A related miss is skipping taxonomy work: a platform classifying against your matter types, issue codes, and custodian structures produces far more useful output than one running on generic categories.
Finally, define the workflow before negotiating the contract. Meaningful flex points in this category include data residency, model isolation, audit rights, and termination terms with data return obligations.
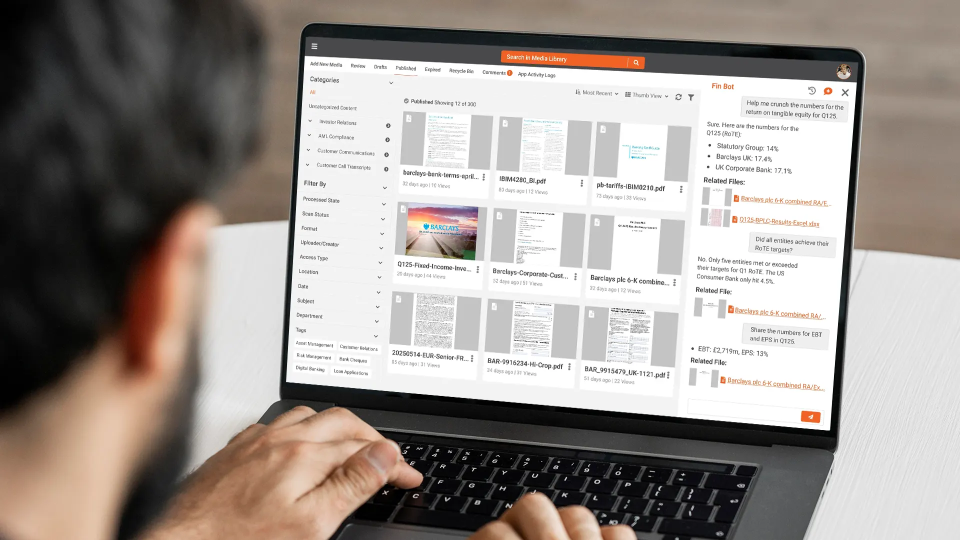
How VIDIZMO Intelligence Hub Handles Legal Document Processing
VIDIZMO Intelligence Hub was built for exactly this kind of workload. A litigation team hands it a case file as it actually exists: boxes of scanned paper, native productions, deposition videos, interview recordings, foreign-language exhibits. What comes back is one searchable case file. The team asks questions in plain English ("where does the witness discuss the licensing terms?") and gets answers that point to the exact page or the exact minute of video they came from, so every finding can be checked against its source before it goes anywhere near a brief.
Sensitive details don't slip through quietly. Anything that looks like personal information or confidential material gets flagged and held for a person to decide, and the platform keeps a record of every step, every source, and every human decision along the way. If a court or opposing counsel ever asks how a result was produced, the answer exists. And because the whole thing can run inside the firm's or agency's own environment, including networks with no outside connection at all, privileged material never leaves the team's control. Legal staff set these workflows up themselves, without writing code and without waiting on IT.
The same intelligent document processing layer that handles litigation productions also clears records backlogs; our companion piece on how IDP cuts document backlogs covers that architecture in depth.
Where Legal Document Processing Goes From Here
Legal teams that treat document AI as a tooling purchase will get incremental savings on review. Teams that treat it as an architectural decision (workflow design, deployment control, audit trails, human oversight) will change the economics of how they litigate, because the matters that were too document-heavy to fight economically stop being so. The constant across both paths is that AI in legal work succeeds when it accelerates research and synthesis under human direction, and fails when it tries to substitute for judgment.
Start with a workflow map rather than a tool shortlist. Document how a production moves from receipt to review today, where recordings sit unwatched, and where foreign-language material gets sampled instead of read. Identify the steps where AI shortens cycle time without compromising defensibility, then evaluate platforms against that map. To see VIDIZMO Intelligence Hub applied to your own case files, request a walkthrough with our team.

About the Author

Jump to
How Intelligent Document Processing Cuts Through Your Data Backlog
AI for Criminal Legal Research: a Practitioner's Guide for 2026


No Comments Yet
Let us know what you think