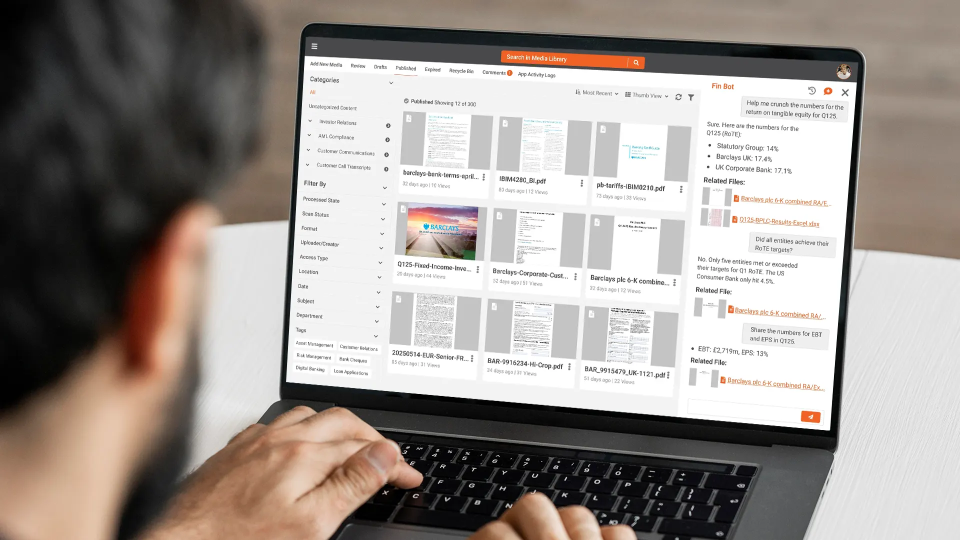
Intelligent document processing (IDP) is a category of AI technology that extracts, classifies, and structures data from unstructured and semi-structured documents. It combines optical character recognition (OCR), natural language processing (NLP), and machine learning to turn invoices, contracts, forms, and scanned records into usable, searchable data. VIDIZMO Intelligence Hub brings IDP into a broader multi-modal AI processing platform, handling documents alongside video, audio, and images through a single pipeline.
If your organization still relies on manual data entry or basic OCR to process incoming documents, you're already behind. The volume of unstructured data doubles roughly every two years, according to IDC's Global DataSphere forecast. Documents make up a significant share of that growth. Invoices, claims, applications, regulatory filings, legal records. They pile up faster than teams can process them.
This guide covers what IDP actually does, where it fits in enterprise workflows, and how organizations across government, healthcare, financial services, and legal industries use it to eliminate bottlenecks.
What Is Intelligent Document Processing and How Does It Work?
IDP goes well beyond traditional OCR. OCR converts images of text into machine-readable characters, but it can't understand context. It doesn't know that "12/15/2025" on an invoice is a due date or that "$47,500" is a line-item total. IDP adds that understanding layer.
A typical IDP pipeline includes four stages:
- Ingestion: Documents arrive as PDFs, scanned images, XML files, emails, or even photographs. The system identifies the file type and routes it to the appropriate processing path.
- Extraction: OCR captures raw text. Layout detection identifies headers, footers, tables, paragraphs, and columns. Pattern recognition pulls structured fields like dates, amounts, names, and account numbers.
- Classification: Machine learning models categorize documents by type (invoice, contract, claim form, patent application) and route them to the correct downstream workflow.
- Validation and output: Extracted data gets checked against business rules, flagged for exceptions, and exported to enterprise systems in structured formats like JSON, CSV, or direct API calls.
The key difference between IDP and simple OCR? IDP understands document structure. It knows that a table on page three contains line items. It recognizes that a signature block at the bottom indicates an executed agreement. And it improves over time as models learn from corrections.
Why Do Organizations Struggle with Unstructured Documents?
Most enterprise data is unstructured. Gartner estimates that unstructured content represents roughly 80% of all enterprise data. Documents sit at the center of that challenge.
Here's where it breaks down in practice:
- Volume overwhelms manual processes. A mid-sized insurance company might receive 50,000 claims per month. Each claim includes forms, medical records, and correspondence. Human reviewers can't keep pace.
- Format inconsistency creates errors. The same type of document arrives as a PDF from one source, a scanned TIFF from another, and an XML feed from a third. Standardizing these manually is tedious and error-prone.
- Compliance demands precision. Healthcare organizations handling Protected Health Information (PHI) under HIPAA can't afford to miss a Social Security number buried in a scanned record. Financial institutions face similar pressure under PCI DSS and anti-money laundering regulations.
- Siloed tools fragment workflows. Many organizations use one tool for OCR, another for classification, and a third for data validation. Each handoff introduces delay and potential data loss.
The real cost isn't just labor. It's the decisions that don't get made because data is trapped in documents nobody has time to read.
Which Industries Benefit Most from Intelligent Document Processing?
IDP applies broadly, but certain industries see outsized returns because of their document volume, regulatory requirements, or both.
Government and Federal Agencies
Federal agencies process enormous volumes of structured and semi-structured documents. Patent applications at the US Patent and Trademark Office, for example, contain complex XML data alongside PDF supporting materials. Freedom of Information Act (FOIA) requests require agencies to review, redact, and release documents under strict deadlines. IDP automates the extraction and classification stages, freeing staff to focus on review and decision-making.
Healthcare
Patient intake forms, insurance claims, lab results, and physician notes all arrive in different formats. IDP extracts relevant data points, flags documents containing PHI for compliance review, and feeds structured output to electronic health record (EHR) systems. The stakes are high: a single missed piece of personally identifiable information (PII) in a disclosure can trigger regulatory penalties.
Financial Services
Loan applications, KYC (Know Your Customer) documentation, tax forms, and audit records create massive processing backlogs. IDP handles extraction of account numbers, tax IDs, and transaction data while applying validation rules that catch discrepancies before they reach downstream systems.
Legal
Law firms and legal departments process contracts, court filings, discovery documents, and regulatory submissions. IDP identifies key clauses, extracts dates and parties, and classifies documents by matter type. For e-discovery workflows, the volume alone makes manual review impractical.
What Should You Look for in an IDP Platform?
Not all IDP tools are built the same. Some handle PDFs well but choke on handwritten forms. Others excel at extraction but can't classify documents or detect sensitive data. Here's what separates a capable platform from a basic one.
Multi-format ingestion
Your platform should handle PDFs, scanned images, XML, JSON, Word documents, and email attachments without requiring format-specific preprocessing. If it also processes non-document content like audio and video, that's a significant advantage, since sensitive data doesn't only live in files.
Layout detection beyond flat text
Tables, multi-column layouts, headers, footers, and nested structures are common in business documents. The platform needs to understand spatial relationships on a page, not just extract text left to right.
PII and sensitive data detection
For regulated industries, extraction isn't enough. The platform should automatically identify PII such as Social Security numbers, tax IDs, account numbers, and health records. Country-specific pattern support matters for multinational organizations: US SSNs follow a different format than UK National Insurance numbers, Indian Aadhaar numbers, or Canadian Social Insurance Numbers.
Classification with trainable models
Pre-built classifiers get you started, but your document types are unique. Look for platforms that let you train classification models on your own taxonomy, whether that's a four-category archival system or a 200-type legal matter classification.
No-code workflow design
Business analysts and operations staff shouldn't need to write Python every time a document format changes. Visual workflow builders let non-technical users modify processing pipelines as requirements evolve.
Deployment flexibility
This matters more than most vendors admit. Government agencies often need on-premises or air-gapped deployments. Healthcare organizations may require private cloud environments. SaaS works for some, but a platform that only offers cloud deployment limits your options.
VIDIZMO Intelligence Hub checks each of these boxes. Its document intelligence capabilities include OCR with layout detection (headers, footers, tables, paragraphs, columns), pattern-based PII detection with country-specific support for US SSN/EIN, UK National Insurance/NHS numbers, Indian Aadhaar, Canadian SIN, and EU Tax IDs. Classification uses supervised and unsupervised learning, and its no-code visual workflow designer is built on LangGraph. Intelligence Hub deploys on SaaS, private cloud, on-premises, or hybrid environments, including air-gapped setups for sensitive government workloads. Explore Intelligence Hub's AI processing capabilities.
How IDP Fits into a Broader AI Processing Strategy
Documents don't exist in isolation. A compliance investigation might involve scanned forms, recorded phone calls, surveillance video, and email correspondence. Processing documents alone gives you a partial picture.
This is where multi-modal AI processing becomes relevant. Instead of running separate tools for document extraction, audio transcription, and video analysis, a unified platform processes all content types through coordinated workflows.
Consider a practical example. A financial services firm receives a suspicious activity report as a PDF with embedded tables. Related evidence includes recorded phone calls, email threads, and transaction logs. A multi-modal pipeline would:
- Extract and classify the PDF report using IDP
- Transcribe the phone recordings in the relevant language (from a pool of 82 supported languages)
- Scan all extracted text for PII and flag sensitive fields
- Run entity extraction across all content types to identify names, dates, and account numbers
- Feed structured output into the investigation management system
That's the strategic shift. IDP as a standalone tool solves one problem. IDP as part of a multi-modal processing platform solves the bigger one: making all your unstructured data actionable.
Intelligence Hub was designed around this principle. Its AI pipeline handles documents, video, audio, and images through a single no-code workflow designer, so organizations don't need four separate tools for four content types.
What Specific IDP Capabilities Drive Real Results?
Mature IDP implementations go beyond basic text extraction. The capabilities that separate production-grade document processing from proof-of-concept demos are the ones that handle edge cases, protect sensitive data, and scale without breaking.
OCR for non-Latin scripts
Standard OCR engines handle Latin scripts well. But organizations working with Arabic, Farsi, or Urdu documents need specialized models trained on right-to-left scripts with connected letter forms. This capability is critical for defense, intelligence, and multinational compliance teams processing documents across multiple regions and languages.
Intelligence Hub includes Perso-Arabic OCR alongside its 82-language transcription support, making it one of the few platforms that handles these scripts natively within the same pipeline as standard document processing.
Pattern-based detection for structured identifiers
Credit card numbers, passport numbers, and Social Security numbers follow predictable patterns. Configurable regex-based detection catches these identifiers even when they appear in unexpected locations, like a handwritten note scanned as part of a larger document package.
Anonymization that preserves data utility
Sometimes you need to share documents without exposing identities. Anonymization replaces sensitive data with neutral placeholders ("Person A," "Organization X") while keeping the document structure intact for analysis. This differs from redaction, which removes or obscures data entirely. Anonymization gives you a usable dataset; redaction gives you a compliant one. Many workflows need both.
File assessment and integrity verification
Before processing begins, intelligent file assessment validates documents through signature analysis (magic bytes), MIME type detection, and integrity checks using MD5 and SHA-256 hashing. The system identifies corrupted files, malware-infected uploads, and non-usable content like temp files or executables before they enter the pipeline. This prevents garbage-in, garbage-out scenarios that waste processing resources.
Deduplication at scale
Large document repositories inevitably contain duplicates. Exact duplicate detection uses cryptographic hashing, while near-duplicate detection applies fuzzy logic algorithms to catch functionally similar files (same content, different formatting). For agencies processing millions of records, deduplication alone can cut processing volume significantly, often by double-digit percentages.
Building IDP Workflows Without Writing Code
One of the biggest barriers to IDP adoption is the technical complexity of building and maintaining processing pipelines. Traditional approaches require data engineers to write custom ETL code for every document type and every format variation.
A visual workflow designer changes this dynamic. Business analysts can drag and drop processing nodes (OCR, classification, extraction, validation, export) into a pipeline, configure each step through a graphical interface, and test the workflow against sample documents. When a new document format arrives or a regulation changes the required extraction fields, the same analyst can update the pipeline without filing a development ticket.
Intelligence Hub's workflow designer uses LangGraph as its orchestration engine, supporting cyclic directed graphs for multi-step workflows. Node types include AI processing, flow control (conditional, loop, switch, parallel), data transformation, human review checkpoints, and integration nodes for HTTP requests and Model Context Protocol (MCP) connections. Workflows are versioned, clonable, and deployable across different portals.
The human-in-the-loop capability deserves special mention. For high-stakes documents like legal filings, compliance submissions, or classified records, you can insert approval checkpoints where a human reviewer validates the AI's extraction before data moves downstream. This builds trust without sacrificing speed.
How Intelligent Document Processing Supports Compliance
Compliance isn't optional, and IDP plays a direct role in meeting regulatory requirements across multiple frameworks.
GDPR and data protection: Automated PII detection identifies personal data across documents, enabling organizations to respond to data subject access requests and follow data minimization principles.
HIPAA: Healthcare document workflows must identify and protect PHI. IDP flags protected health information during extraction, routing sensitive documents through compliant handling paths.
FOIA: Government agencies responding to public records requests need to identify, review, and redact sensitive information in documents before release. IDP automates the identification phase, dramatically reducing the time from request to response.
NIST Privacy Framework: Organizations aligning with NIST privacy controls benefit from automated data inventory and classification capabilities that IDP provides across document repositories.
Intelligence Hub is ISO 27001:2022 certified (Certificate #RA-2507091, issued by Risk Associates Europe Ltd). It supports FedRAMP deployments through hosting on ProjectHost's FedRAMP-authorized environment and supports HIPAA-compliant deployments. For organizations that need to keep sensitive documents on their own network, Intelligence Hub offers on-premises and air-gapped deployment options with self-hosted LLMs through Ollama and VLLM, ensuring no data leaves the organization's perimeter.
Contact us to see how Intelligence Hub automates document and multimedia processing.
Getting Started with Intelligent Document Processing
The organizations getting the most value from IDP didn't start by processing every document type at once. They picked one high-volume, high-pain workflow (claims processing, FOIA requests, patent applications) and built from there.
Start by auditing your document backlog. How many document types do you process monthly? What percentage arrive as scanned images versus digital PDFs? Where do bottlenecks occur? The answers shape your IDP requirements.
Then evaluate platforms against the criteria that matter for your environment: multi-format support, PII detection depth, deployment flexibility, and the ability to modify workflows without developer involvement.
If your organization processes documents alongside other unstructured content like recorded calls, video evidence, or multimedia correspondence, consider a multi-modal platform that handles all content types in a unified pipeline. That's the approach Intelligence Hub takes, and it eliminates the integration overhead of stitching together four or five point solutions.