by Ali Rind, Last updated: July 15, 2026
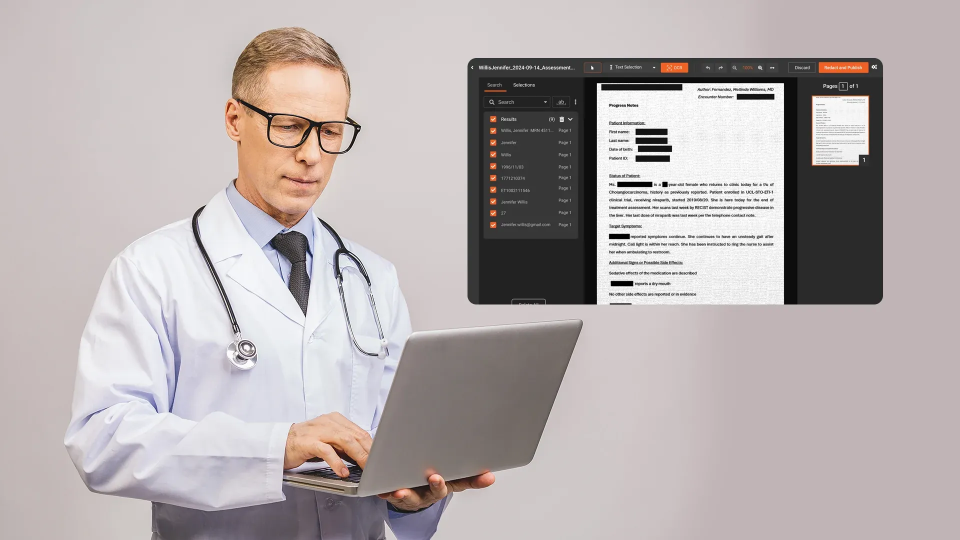
A three-person compliance team at a regional health system receives a records request. It covers 14 months of patient documentation: discharge summaries, lab reports, imaging orders, insurance correspondence, and physician notes. The total: 4,200 pages across 380 files. Every page must be reviewed for Protected Health Information (PHI) and redacted before release.
At an average rate of two to three minutes per page for manual redaction, this single request represents roughly 140 to 210 hours of work. That is five to seven weeks of full-time effort from one analyst, or the entire team doing nothing else for two weeks.
This is the math that breaks small healthcare compliance teams. The document volumes are enormous. The headcount is not. And hiring more staff is rarely an option.
This post covers why manual redaction does not scale for healthcare organizations, how automation changes the economics, and what a practical automated redaction workflow looks like for lean teams.
The Volume Problem: Healthcare Documents at Scale
Healthcare generates more documentation per patient interaction than almost any other industry. A single inpatient stay can produce dozens of discrete documents, and each one may contain PHI that must be redacted before it can be shared, released, or archived.
The document types that drive volume:
- Clinical records: progress notes, discharge summaries, history and physical reports, consultation notes, operative reports
- Lab and diagnostic reports: pathology results, radiology reports, blood work, genetic testing
- Medication records: prescription histories, medication administration records, pharmacy communications
- Insurance and billing documents: Explanation of Benefits (EOBs), claims submissions, pre-authorization letters, denial correspondence
- Administrative records: consent forms, advance directives, patient demographics, insurance enrollment
- Imaging files: scanned paper records, faxed documents, photographed forms that exist only as images
What makes this overwhelming for small teams:
A 200-bed community hospital might process 500+ records requests per year. A multi-site physician group managing 50,000 patient encounters annually generates tens of thousands of pages per quarter that require redaction for various purposes: compliance audits, legal discovery, payer requests, research data sharing, and patient access requests under HIPAA's Right of Access provision.
The compliance team handling these requests is typically two to five people. They are also responsible for policy development, training, incident response, and audit preparation. Redaction is one of many responsibilities, and it consumes a disproportionate share of their time.
Why Manual Redaction Breaks Down
Manual redaction is not just slow. At scale, it introduces risks that compound over time.
Throughput Limitations
The math is straightforward. Manual redaction of healthcare documents averages two to four minutes per page, depending on document complexity and PHI density. For a team of three handling 500 requests per year averaging 200 pages each:
- Total pages per year: 100,000
- Manual redaction time: 200,000 to 400,000 minutes (3,300 to 6,600 hours)
- FTE equivalent: 1.6 to 3.2 full-time employees doing nothing but redaction
That leaves zero capacity for every other compliance function the team is responsible for.
Consistency Erosion
Human reviewers are effective at catching obvious PHI such as patient names in header fields and dates of birth in demographic blocks. They are less reliable with:
- Non-standard identifiers: account numbers, health plan beneficiary numbers, and device serial numbers that do not follow a recognizable pattern
- Embedded text in images: scanned documents, faxed records, and photographed forms where PHI exists as pixels, not searchable text
- Multi-page context: a patient name appears on page one of a 40-page document; by page 30, the reviewer has been scanning for an hour and misses a reference to the same patient in a nested table
- Partial identifiers: a combination of date, zip code, and age that individually seem harmless but together constitute individually identifiable information under HIPAA
Error rates in manual redaction increase with volume and fatigue. A team processing 400 pages per day will produce more misses in the afternoon than the morning, and more on Friday than Monday.
Backlog Accumulation
When redaction throughput cannot match request volume, backlogs grow. Backlogs create downstream problems:
- HIPAA Right of Access requires covered entities to respond to patient record requests within 30 days (with a possible 30-day extension). Backlogs push response times past these deadlines.
- Legal discovery timelines are set by courts and opposing counsel. Missing a production deadline because of redaction capacity has direct legal consequences.
- Research timelines are governed by grant deadlines and multi-site coordination schedules. A redaction backlog at one site can delay an entire study.
- Audit responses to federal and state regulators carry their own deadlines. Slow redaction means slow compliance.
How Automation Changes the Economics
Automated redaction does not eliminate human judgment from the process. It eliminates the mechanical work: scanning every page for PHI, drawing redaction boxes, and verifying coverage. It then focuses human effort on the decisions that actually require expertise.
What Automation Handles
AI-powered PII/PHI detection scans every page of every document and identifies:
- Patient names, dates of birth, ages, and demographic data
- Medical record numbers (MRNs), health plan beneficiary numbers, and account numbers
- Social Security numbers, addresses, phone numbers, and email addresses
- Provider identifiers such as physician names, NPI numbers, and facility names
- Dates (admission, discharge, service, prescription) that constitute identifiable information
- Custom identifiers specific to the organization, including internal coding systems and department-specific numbering
Detection runs across all document formats: PDFs, Word documents, spreadsheets, scanned images, and faxed records (via OCR). For scanned and image-based documents, which are pervasive in healthcare due to legacy paper records and fax workflows, OCR converts pixel-based text into searchable content before PII detection runs.
Automated redaction then applies the configured treatment (black box, text removal, or replacement) to every detected PHI instance across the document set.
What Humans Handle
With automation handling detection and application, the compliance team's role shifts to:
- Policy configuration: defining which PII types to detect, setting confidence thresholds, and creating custom patterns for organization-specific identifiers
- Exception review: reviewing items flagged by AI that fall below the confidence threshold or that match multiple possible classifications
- Quality assurance: spot-checking a sample of redacted documents to validate accuracy
- Audit trail oversight: reviewing the log of what was detected and redacted for each request
This is a fundamentally different workload. Instead of three analysts spending 100% of their time on manual redaction, they spend 10 to 20% on oversight and validation, freeing capacity for the compliance functions that actually require human expertise.
The Throughput Difference

Building an Automated Redaction Workflow for Small Teams
A practical automated workflow for a lean healthcare compliance team has four stages.
Stage 1: Intake and Classification
Documents arrive from multiple sources: patient access requests, legal holds, audit demands, and research data pulls. The intake step organizes incoming documents for processing:
- Batch incoming files by request type and priority
- Identify document formats (native PDF, scanned PDF, Word, image-only)
- Flag documents requiring OCR preprocessing (scanned records, faxed documents)
Stage 2: Automated Detection and Redaction
This is the bulk of the work, and the part that automation handles without human intervention:
- OCR preprocessing converts scanned documents and images into searchable text
- AI detection identifies all PII/PHI types configured in the organization's redaction policy
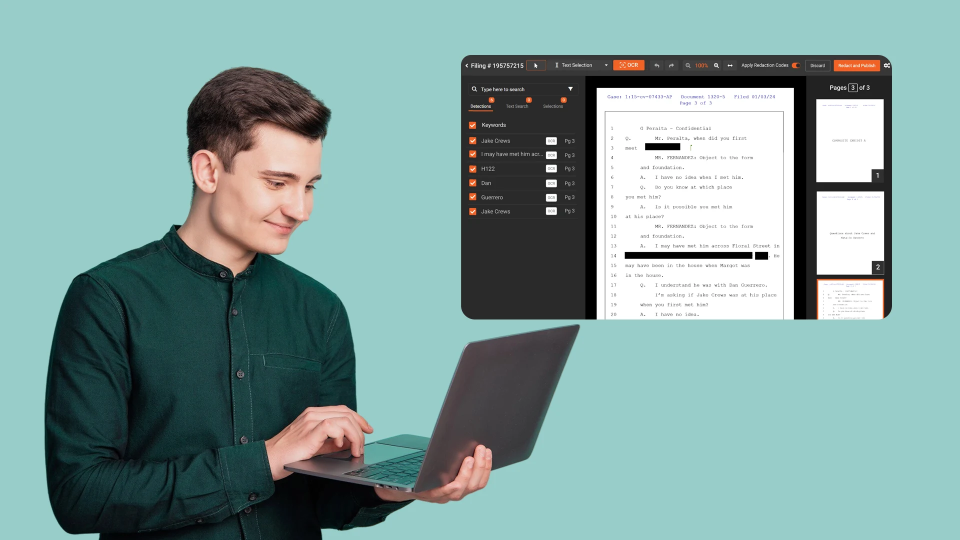
- Pattern matching catches structured identifiers (SSNs, MRNs, dates in standard formats)
- Contextual AI recognition catches unstructured identifiers such as names in narrative text, identifiers in non-standard formats, and partial identifiers that pattern matching alone would miss
- Automated redaction applies the configured treatment to all detected PHI
For high-volume requests, batch processing handles hundreds of files simultaneously. Queue-based automation lets teams submit large document sets for overnight processing. A 4,200-page request submitted at 5 PM is processed and ready for review the next morning.
Stage 3: Human Review and Validation
The compliance team reviews the AI output, not every page, but the items that need human judgment:
- Low-confidence detections: items where the AI confidence score falls below the team's configured threshold, flagged for manual verification
- Potential false positives: items detected as PHI that may actually be non-sensitive content (common with generic names that also appear as medical terms)
- Spot-check sample: a random percentage of pages reviewed to validate overall accuracy
Split-screen comparison tools accelerate this review: the reviewer sees the original and redacted versions side by side, clicking through flagged items rather than scanning pages sequentially.
Stage 4: Export, Distribute, and Document
The final stage produces the redacted output and generates compliance documentation:
- Export redacted documents in the required format (redacted PDF is most common for external distribution)
- Generate the audit trail documenting what was detected, what was redacted, who reviewed, and when
- Distribute to the requesting party through the appropriate secure channel
- Archive the redaction record for compliance documentation
Custom Redaction Rules: Adapting to Your Organization
Every healthcare organization has identifiers that are unique to its systems, including internal patient numbering, department-specific codes, and proprietary form layouts. A practical automated redaction tool lets teams define custom detection rules beyond the standard PII types:
- Custom regex patterns for organization-specific identifier formats (e.g., a 7-digit MRN with a specific prefix, a facility code embedded in account numbers)
- Context words that help the AI distinguish between sensitive and non-sensitive uses of the same pattern (e.g., "patient" or "DOB" appearing near a date increases the likelihood that the date is PHI)
- Redaction templates for recurring document types: once configured for a standard discharge summary layout or a specific payer's EOB format, the template applies automatically to all future documents of that type
These custom rules accumulate organizational knowledge. The initial configuration takes time, but each new rule reduces future manual review. The system gets more accurate with every document type it learns.
Compliance Documentation: The Audit Trail Advantage
For small teams, the audit trail generated by automated redaction is as valuable as the redaction itself. Manual redaction produces a redacted document but no documentation of the process. If a regulator or auditor asks how the team determined what to redact, the answer is "an analyst reviewed it," with no supporting detail.
Automated redaction generates a structured log for every file processed:
- What was detected: each PHI instance identified, its type, location in the document, and confidence score
- What was redacted: the treatment applied (black box, text removal) and the final state
- Who reviewed: the analyst who validated the AI output, with timestamp
- What was overridden: any AI detections that the reviewer accepted or rejected, with the reviewer's rationale
This documentation transforms compliance from "we believe we caught everything" to "here is the auditable record of exactly what was found, what was redacted, and who approved it."
How VIDIZMO Redactor Supports Small Healthcare Teams
VIDIZMO Redactor provides the automation backbone that lean compliance teams need to handle healthcare document volumes without adding headcount.
AI-powered detection at scale:
- 40+ PII/PHI types detected automatically, including patient names, MRNs, dates of birth, SSNs, health plan numbers, and provider identifiers
- Both pattern matching and contextual AI recognition (NLP/LLM-based), catching PHI in narrative text and non-standard formats that rule-based systems miss
- OCR for scanned documents, faxed records, and image-based files, including handwritten text recognition (ICR) for legacy paper records
- Custom PII patterns (regex + context words) for organization-specific identifiers
Bulk processing built for volume:
- Batch processing tested with 1.1 million+ files
- Queue-based automation for overnight and off-hours processing: submit document sets at end of day, review results the next morning
- Bulk redaction with predefined templates for recurring document types
- 255+ file formats supported, including PDFs, Word, Excel, PowerPoint, images, and scanned documents
Multi-format coverage in one platform:
- Document, image, video, and audio redaction in a single tool, with no separate platform needed when a records request includes surveillance footage, recorded calls, or medical imaging alongside documents
- Objects inside PDFs: detects and redacts faces, license plates, and other visual PII embedded as images within PDF documents (a key gap in text-only redaction tools)
- DICOM support for organizations that also handle medical imaging files
Review and compliance:
- Split-screen comparison for efficient human review of AI output
- Configurable confidence thresholds (25% to 90%), allowing teams to set the sensitivity appropriate to the request type
- Comprehensive audit trails documenting every detection, redaction, and review decision
- Redaction copy generation preserves originals while creating separate redacted output files
- Supports HIPAA-compliant deployments with BAA/DPA available
Deployment flexibility:
- SaaS, government cloud, on-premises, and hybrid deployment: patient records never leave the organization's approved environment
- No client-side GPU required, as all AI processing runs server-side
Talk to a redaction specialist about automating your healthcare compliance workflow. Request a demo.

Conclusion
Small healthcare compliance teams face a structural mismatch: the volume of documents requiring PHI redaction grows with every patient interaction, records request, and regulatory obligation, but the team does not grow with it. Manual redaction consumes capacity that these teams need for policy work, training, incident response, and audit preparation.
Automated redaction reverses the equation. AI-powered detection and bulk processing handle the mechanical work at machine speed. Human review shifts from page-by-page scanning to exception-based validation. And audit trails provide the compliance documentation that manual processes cannot.
The result is a team that handles the same document volumes, or larger, with the same headcount, while producing more consistent, more defensible, and more auditable redaction output.
Frequently Asked Questions
Manual redaction averages two to four minutes per page. Automated redaction processes documents in bulk. A 1,000-page batch runs through AI detection and redaction as a single job, with human review focused only on flagged exceptions (typically 2 to 4 hours for the batch rather than 33 to 67 hours of page-by-page manual work). The exact savings depend on document complexity and PHI density.
Yes. OCR (Optical Character Recognition) converts scanned documents, faxed records, and image-based files into searchable text before PII detection runs. This includes handwritten text recognition (ICR) for legacy paper records that were never digitized. The accuracy of OCR-based detection depends on scan quality, but AI-powered systems handle the range of quality levels common in healthcare document workflows.
Custom PII patterns let teams define regex-based detection rules for organization-specific identifier formats, combined with context words that help the AI distinguish between sensitive and non-sensitive uses. Once configured, these custom rules apply automatically to all future documents, building institutional knowledge into the redaction system.
AI detection accuracy depends on document quality and PHI density, but configurable confidence thresholds give teams control over the trade-off. Setting a higher threshold (e.g., 80 to 90%) means more items get flagged for human review, increasing confidence that nothing is missed at the cost of more false positives to review. Most teams adopt a risk-based approach: higher sensitivity for externally shared documents, standard sensitivity for internal use.
The PII/PHI detection capabilities cover the identifier types required by both HIPAA (18 categories of individually identifiable health information) and Canada's Personal Health Information Protection Act (PHIPA). Custom pattern configuration can address jurisdiction-specific identifier formats such as Ontario Health Insurance Plan numbers and provincial health card formats that differ from US standards.
About the Author

Jump to
How to Redact Documents Before Uploading to AI Tools Like ChatGPT

HIPAA Redaction Rules: A Complete Guide to Protecting PHI in 2026

No Comments Yet
Let us know what you think