by Ali Rind, Last updated: July 15, 2026
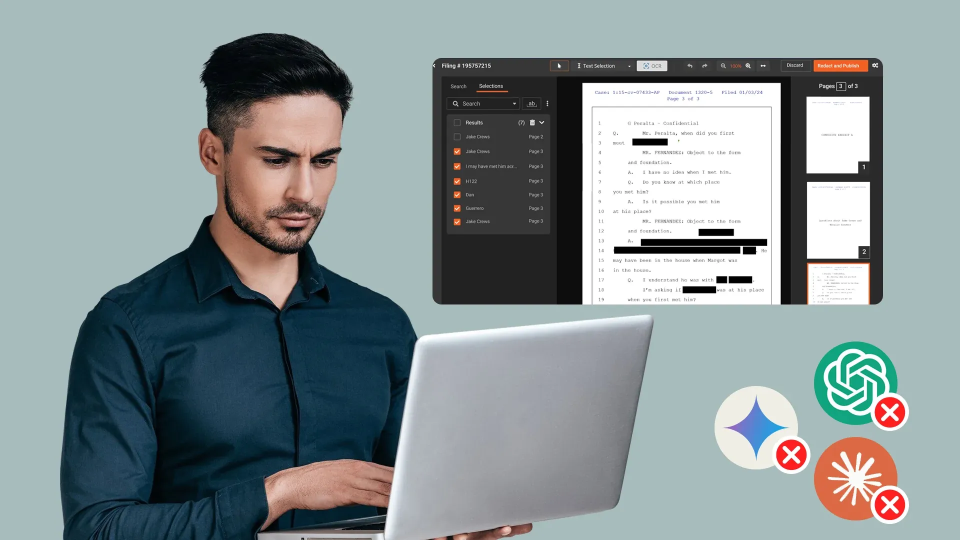
Organizations are rushing to adopt AI platforms, from large language models (LLMs) to document analysis tools, to automate workflows, generate insights, and accelerate decision-making. But in this rush, many overlook a critical risk: LLM redaction risk, the exposure of personally identifiable information (PII), protected health information (PHI), and other sensitive data when unredacted content is fed into AI systems.
Every document, recording, or transcript uploaded to an AI platform becomes potential training data. Without proper redaction before submission, organizations risk regulatory violations, data breaches, and irreversible privacy harm. This article explores why AI data privacy demands that organizations implement secure redaction workflows before any content touches an AI platform.
What Is LLM Redaction Risk?
LLM redaction risk refers to the danger of sensitive information being ingested, stored, or memorized by large language models and other AI systems when organizations submit unredacted content for processing.
When documents containing Social Security numbers, medical records, financial details, or other PII are uploaded to AI platforms, that data may be exposed in several ways:
Retained in platform logs. Even if the AI provider claims not to train on user data, uploaded content may be stored temporarily for processing, debugging, or quality assurance purposes.
Incorporated into model training. Many AI platforms include clauses allowing data use for model improvement unless users explicitly opt out. Once sensitive data enters training pipelines, it cannot be retrieved or deleted.
Exposed through model outputs. Research has demonstrated that LLMs can memorize and reproduce training data, including PII, when prompted in specific ways (Carlini et al., "Extracting Training Data from Large Language Models"). A Social Security number uploaded in one session could surface in another user's query results.
Shared with third-party subprocessors. AI platforms frequently rely on cloud infrastructure providers and subprocessors, expanding the data exposure surface beyond the primary vendor.
The fundamental problem is irreversibility. Unlike a database breach where access can be revoked, once PII enters an AI model's weights through training, there is no practical way to extract it. This makes AI training data privacy a fundamentally different challenge from traditional data security.
Types of Sensitive Content at Risk in AI Workflows
Organizations regularly process content types that contain embedded sensitive information, and many are now being fed directly into AI platforms without adequate preparation.
Documents and PDFs. Contracts, court filings, medical records, financial statements, HR files, and insurance claims routinely contain PII such as names, addresses, Social Security numbers, account numbers, and dates of birth. AI document security requires that this data be removed before any automated processing occurs.
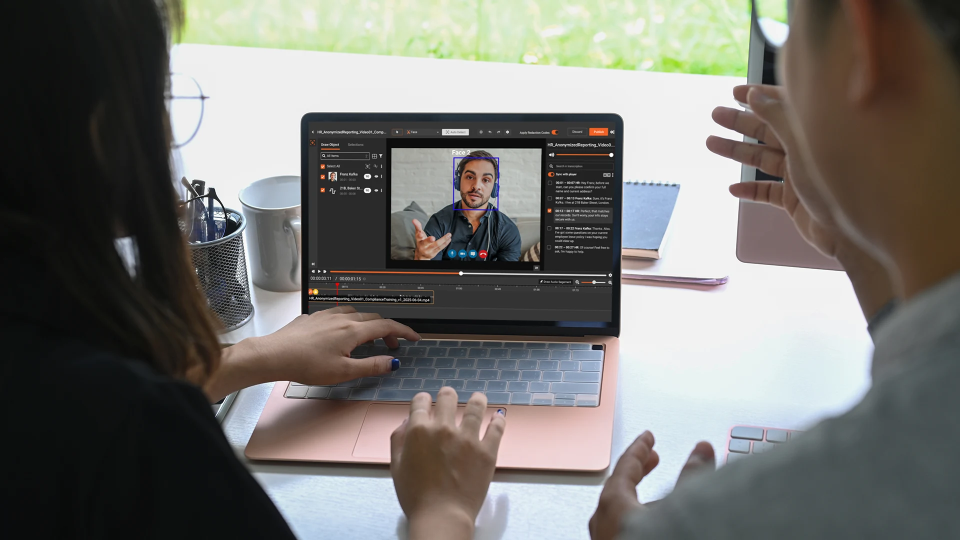
Audio and video recordings. Call center recordings, depositions, body camera footage, telehealth sessions, and meeting recordings contain spoken PII including names, account numbers, and medical details that transcription and AI analysis tools capture and store.
Images. Scanned documents, identity cards, medical images, and photographs may contain visible PII that AI vision models can extract and index.
Transcripts and metadata. Even AI-generated transcripts and metadata fields can carry sensitive data if the source content was not redacted before processing.
The scope of exposure grows with every AI use case an organization adopts. A compliance team using AI to review contracts, a legal team summarizing depositions, a healthcare organization analyzing patient records: each workflow creates a new vector for PII redaction failures.
Redaction vs Masking: A Critical Distinction for AI Security
Organizations sometimes confuse redaction with masking. The difference is critical when protecting data sent to AI platforms.
Masking replaces sensitive data with placeholder characters (for example, replacing a Social Security number with "XXX-XX-XXXX") in the displayed output while potentially retaining the original data in the underlying file, database, or system. Masking is a presentation-layer control. The actual data still exists and can be recovered.
Redaction permanently removes or obscures sensitive information from the source content. A properly redacted document, audio file, or video does not contain the original PII in any recoverable form. The redacted copy is what gets shared, processed, or submitted to external systems.
For AI workflows, this distinction is non-negotiable. If content is merely masked before being uploaded to an AI platform, the underlying PII may still be accessible through the file's metadata, embedded text layers, or raw data streams. The AI platform ingests the actual file, not just what appears on screen.
Secure redaction ensures that data leaving your organization's boundary has been permanently stripped of sensitive information. Masking creates a false sense of security that regulatory auditors and litigation discovery processes will not accept.
The Hidden Danger of Manual Redaction in AI Workflows
Many organizations still rely on manual redaction, with staff reviewing documents page by page and blacking out sensitive fields by hand or using basic PDF tools. Manual redaction risk compounds significantly in AI-adjacent workflows for several reasons.
Inconsistency. Human reviewers miss PII at predictable rates, especially in high-volume environments. A name redacted on page three may be missed in a footer on page forty-seven. When these partially redacted documents are uploaded to an AI platform, the missed PII enters the system permanently.
Scale mismatch. Organizations adopting AI platforms do so precisely because they process large volumes of content. Manual redaction cannot keep pace with the throughput AI workflows demand. The result is either a bottleneck that slows AI adoption or corner-cutting that leaves sensitive data exposed.
Format limitations. Manual approaches typically cover one format, usually documents, while leaving video, audio, and images unaddressed. An organization may manually redact a PDF but feed the accompanying audio recording directly into an AI transcription service without any PII removal.
No defensible audit trail. Manual redaction processes rarely generate the kind of audit trail that compliance requirements demand. When a regulator asks how PII was protected before AI processing, manual review does not meet the evidentiary standard that a documented, automated workflow provides.
Manual redaction was designed for a world where content stayed within organizational boundaries. In an era where content is routinely sent to external AI platforms for processing, manual approaches create unacceptable gaps in document redaction coverage.
How Secure Redaction Protects AI Training Data Privacy
VIDIZMO Redactor is an AI-powered redaction platform that supports secure redaction across video, audio, images, documents, and PDFs in a single workflow, covering 255+ file formats.
It acts as the pre-processing layer between your content and any AI platform, ensuring sensitive data is permanently removed before it crosses your organizational boundary.
-
Multi-format PII detection automatically identifies faces, license plates, spoken PII, and text-based identifiers across all media types, including scanned and handwritten documents via OCR.
-
Configurable confidence thresholds from 25% to 90% let compliance teams balance automation speed with accuracy, routing edge cases to human reviewers where needed.
-
Bulk processing at scale handles high-volume content overnight or during off-peak hours, keeping redaction workflows from becoming a bottleneck in AI adoption.
-
Defensible audit trails log every detection and redaction action, meeting documentation requirements under HIPAA, GDPR, CCPA, and CJIS.
-
Flexible deployment across SaaS, on-premises, government cloud, and hybrid models ensures the redaction workflow itself meets your data residency requirements.
Rather than relying on an AI vendor's data handling promises, VIDIZMO Redactor puts PII redaction under your organization's direct control before any content reaches an external platform.
Start your free trial of VIDIZMO Redactor and build a compliant pre-AI redaction workflow today.

Key Takeaways
- Feeding unredacted content into any AI platform is a compliance violation, regardless of the vendor's privacy policy.
- Your organization remains liable for what enters an AI pipeline. Vendor certifications like SOC 2 or a signed BAA do not transfer that responsibility.
- Masking is not redaction. AI platforms ingest raw files, not masked displays. Only permanent redaction removes PII from the source.
- Manual redaction cannot scale. It misses PII, skips audio and video, and produces no defensible audit trail.
- Risk exists across every content type: video, audio, documents, images, transcripts, and metadata all carry PII that AI platforms will process and potentially retain.
- A secure pre-AI redaction workflow must be automated, cover all formats, and generate a complete audit trail to satisfy HIPAA, GDPR, CCPA, and CJIS requirements.
- VIDIZMO Redactor removes sensitive data before it reaches any AI platform, putting compliance control in your hands, not your vendor's.
Frequently Asked Questions
LLM redaction risk is the exposure of sensitive data, such as PII or PHI, when unredacted content is uploaded to an AI platform. The data can be retained in logs, used for model training, or reproduced in outputs. Once it enters a model's training pipeline, it cannot be removed.
Redaction significantly reduces compliance risk by ensuring PII never reaches the AI platform in the first place. It is the most defensible control available, but it should be paired with an audit trail, role-based access controls, and a documented workflow to fully satisfy regulations like HIPAA, GDPR, and CJIS.
No. Most AI platform terms of service include clauses that permit data use for model improvement unless users explicitly opt out. Even with opt-out provisions, content may be temporarily retained in logs or shared with subprocessors. Redacting PII before upload removes the risk regardless of vendor policy.
No. Masking hides data at the presentation layer but leaves the original PII intact in the underlying file. AI platforms process the raw file, not the masked display. Only permanent redaction removes the data from the source and provides defensible protection.
Audio and video recordings carry the highest risk because spoken PII is frequently overlooked. Documents, scanned images, and metadata fields are also high-risk. Organizations often redact PDFs but feed call recordings, depositions, and meeting transcripts into AI tools without any PII removal.
Standard redaction prepares content for human review or public disclosure. Pre-AI redaction specifically addresses the risk of PII entering an AI pipeline, where it can be memorized, indexed, or reproduced at scale. It requires broader format coverage, higher processing volume, and tighter audit controls than traditional redaction workflows.
No. Manual redaction is too slow, inconsistent, and format-limited for AI-scale workflows. It typically covers documents but misses audio, video, and metadata. It also fails to produce the kind of automated audit trail that regulators expect when sensitive content is being prepared for AI processing.
About the Author

Jump to

How to Redact Sensitive Data in Excel Spreadsheets
How Consulting Firms Can Redact PII from Client Demo & Presentation

No Comments Yet
Let us know what you think