by Zain Noor, Last updated: May 4, 2026

AI-powered PII redaction software helps organizations achieve compliance by automatically removing personally identifiable information (PII) from videos, audio recordings, and documents—saving time, reducing human error, and improving data security.Let’s face it, handling sensitive information comes with serious risks. Every unredacted name, address, or financial detail in a document, video, or audio file is a potential data breach waiting to happen.
According to the IBM Cost of a Data Breach Report 2024, the average data breach cost has soared to $4.88 million. For law enforcement agencies, legal teams, and compliance officers, failing to redact personally identifiable information (PII) properly can lead to severe legal penalties, loss of public trust, and reputational damage.
Despite these risks, many organizations still rely on manual redaction methods—a time-consuming, error-prone process that drains valuable resources. Imagine a FOIA officer scrambling to redact hours of bodycam footage or hundreds of legal documents under tight deadlines, only to miss a critical detail that later results in a compliance violation. The frustration is accurate, and so are the consequences.
This is where an automated PII redaction solution makes a measurable difference. By using automatic redaction software, organizations can securely redact sensitive data across video, audio, and document formats while significantly reducing time, effort, and operational costs.This blog will explore the biggest challenges in PII redaction and how automated redaction software can provide an efficient, scalable solution.
The Growing Challenge of Personally Identifiable Information (PII) Redaction
Sensitive data is everywhere. The mountain of Personally Identifiable Information (PII) that organizations handle grows by the minute, from customer names and emails to health records and social security numbers. And as companies evolve with digital transformation, this volume only continues to swell.
However, manually redacting sensitive data from documents, images, or videos without a Manual redaction might sometimes be as risky as not reacting at all. One missed detail, and your organization could be staring at massive fines or, worse, a damaged reputation.
The stakes are high. The regulatory landscape demands near-perfect compliance, while client trust demands unassailable security. Yet, traditional redaction methods often fail to deliver on these needs. It’s time for organizations to evaluate and adopt PII redaction software seriously.
Why Traditional Redaction Methods Fail Without PII Redaction Software
Organizations that rely on manual processes or basic digital tools instead of a modern data redaction software solution often struggle with significant accuracy, scalability, and compliance gaps. Here’s why these traditional methods just aren’t cutting it anymore:
- Human Error and Oversight: It’s easy to overlook details, especially in dense documents with layered data.
- Time-Intensive Processes: Manually redacting hundreds of documents requires not just significant time but also substantial manpower, which directly impacts productivity and costs.
- Lack of Scalability: As your organization grows and data increases, redacting PII at scale becomes unsustainable.
- Risk of Inconsistent Redaction: Without consistent standards, manual redaction may result in one document being redacted correctly while another has exposed data.
The bottom line? Traditional redaction methods can be time-consuming, error-prone, and inconsistent. At the speed and scale today’s data environment demands, they’re just not up to the task. And with mounting pressure from regulators and customers, these limitations translate directly into risk and liability for your organization.
Key Pain Points Solved by Modern PII Redaction Software
Let’s dig deeper into the key pain points that professionals like Compliance Officers, IT Security Managers, and Legal Counsel feel when handling PII redaction.
Balancing Compliance and Efficiency
Maintaining stringent compliance regulations like GDPR, HIPAA, and CCPA is daunting. Every piece of data needs to meet these standards. The challenge? Ensuring compliance without stifling productivity or draining resources. Legal and Compliance teams are stretched thin, trying to keep up with routine tasks and strict regulatory demands, often leading to burnout and inefficiency.
Risk of Regulatory Non-Compliance
Regulators have zero tolerance for slip-ups when it comes to data privacy. A single oversight can lead to hefty fines or, in severe cases, even business shutdowns. The constant worry about regulatory audits and compliance checks keeps Compliance Officers on edge, knowing that one missed PII element could spell disaster.
Take GDPR penalties as an example. These fines can reach up to €20 million or 4% of global revenue. If this seems drastic, consider the ripple effects: the news of a data breach spreads quickly, eroding consumer trust and leading to revenue loss far beyond the immediate penalty.
Inconsistent Data Handling Standards Across Teams
Many organizations have multiple teams handling sensitive data without standardized redaction protocols. This inconsistency increases the risk of data leaks and adds a layer of complexity to data governance, further complicating compliance.
Time-Consuming Manual Redaction Processes
For agencies and enterprises handling large volumes of sensitive data, PII redaction without specialized redaction software for law enforcement and compliance teams becomes a mundane, repetitive, and labor-intensive task, spending hours combing through documents to redact sensitive information is inefficient and costly. IT Security Managers and Operations Teams feel this pinch as they spend more resources on redaction than on strategic, growth-driving initiatives.
These challenges create a complex, high-pressure environment for organizations. With traditional redaction methods, teams feel trapped between maintaining strict compliance and protecting productivity.
Why AI-Powered PII Redaction Software Is the Best Solution
Thankfully, AI-powered redaction software has evolved to tackle these challenges head-on. Here’s how advanced redaction software solves these pain points:
Automated, Accurate Redaction
Personally identifiable information redaction uses powerful algorithms and machine learning to automatically identify and redact sensitive information, ensuring accuracy with minimal human intervention. This feature alone tackles several pain points:
- Error Reduction: By automating the identification process, software reduces the risk of oversight.
- Consistency: Automated tools standardize redaction across documents, ensuring compliance and consistency.
Scalability for Growing Data Needs
As organizations scale, so does their data. Modern redaction software is built to handle large volumes of data quickly and efficiently, offering the scalability that traditional methods cannot match. This ability to scale is essential for teams managing thousands of documents, freeing them from manual redaction bottlenecks.
Enhanced Compliance and Audit Trails
Leading PII redaction software solutions also offer built-in audit trails, which record all redactions made. These logs are invaluable during regulatory audits, making demonstrating compliance easier and avoiding potential fines.
Increased Efficiency and Productivity
With automated redaction, teams spend less time on labor-intensive tasks and more time on strategic, impactful work. PII redaction software is an efficiency multiplier, helping organizations streamline processes while staying compliant. This frees up valuable resources, enabling teams to focus on growth, security, and innovation.
Adaptability to Industry-Specific Standards
Advanced redaction software often includes industry-specific templates that make it easy to tailor redaction settings to meet compliance standards, like HIPAA for healthcare or GDPR for companies handling EU data. This adaptability is essential for organizations operating across regulated sectors.
Manual Redaction vs Automated PII Redaction Software
While manual redaction may work for small volumes of data, it quickly becomes inefficient and risky at scale. Automated PII redaction software eliminates inconsistencies by using AI to accurately detect and redact sensitive information across documents, audio, and video—making it the preferred choice for organizations facing strict compliance deadlines and growing data volumes.
-May-04-2026-10-18-46-5107-PM.png?width=1457&height=771&name=image%20(3)-May-04-2026-10-18-46-5107-PM.png)
Who Should Use PII Redaction Software? Key Industry Use Cases
Law Enforcement and Public Safety
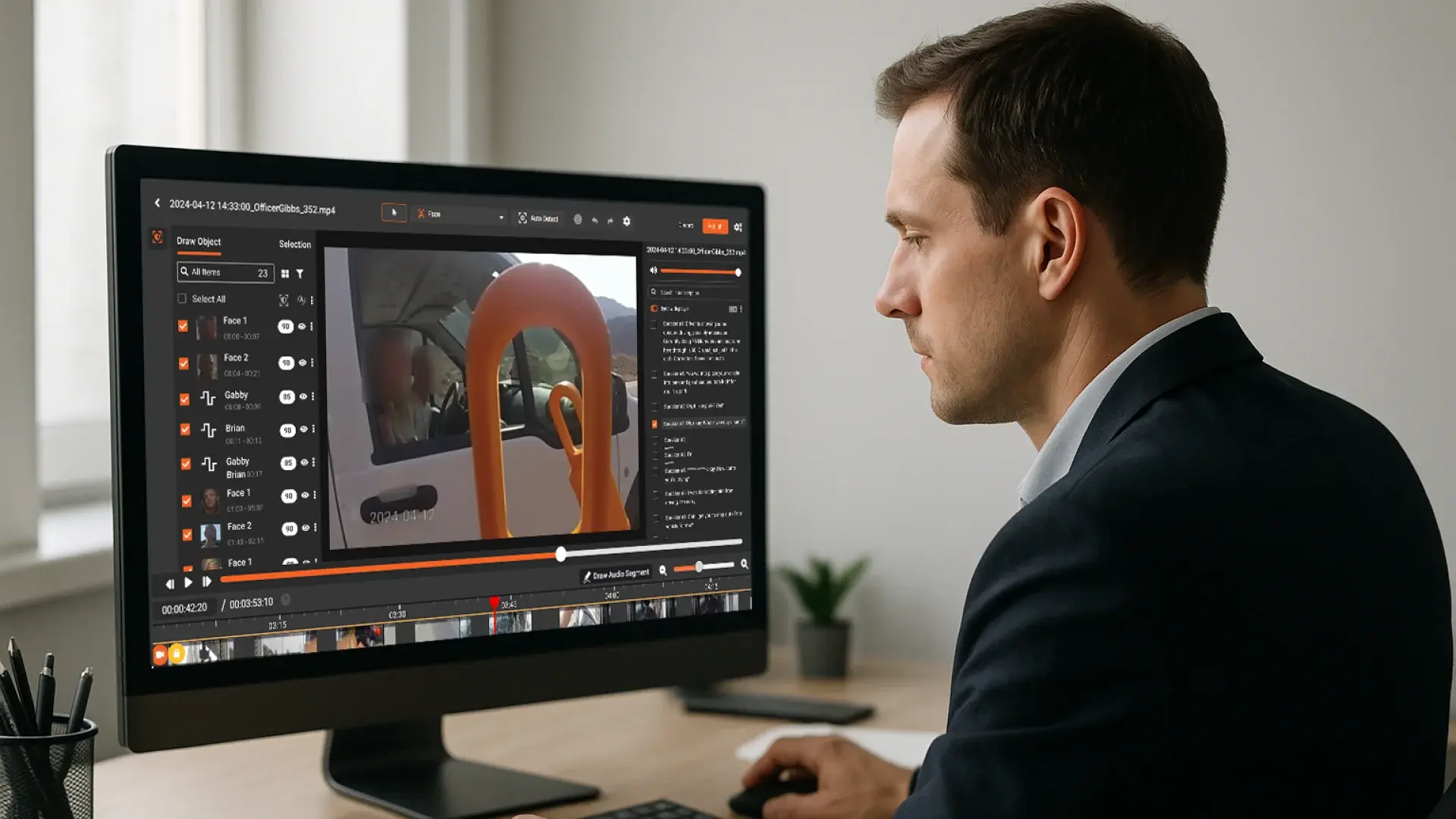
Law enforcement agencies handle vast amounts of sensitive data through body-worn cameras, dashcams, and interview recordings. PII redaction software for law enforcement enables agencies to automatically redact faces, license plates, and spoken PII to meet FOIA and CJIS compliance requirements while accelerating evidence release.
Legal and Compliance Teams
Legal teams and compliance officers regularly manage contracts, case files, and discovery documents containing sensitive information. An automated PII redaction solution helps ensure regulatory compliance by accurately redacting personally identifiable information from large volumes of legal documents under tight deadlines.
Healthcare and Financial Services
Highly regulated industries such as healthcare and finance must comply with HIPAA, GDPR, and data privacy laws. AI-powered data redaction software helps organizations securely redact patient records, financial data, and customer information while maintaining audit-ready compliance.
Government and Public Sector Organizations
Government agencies frequently respond to public records requests and data-sharing mandates. A scalable PII redaction tool allows agencies to efficiently redact sensitive data from documents, videos, and audio files before public release, reducing risk and improving transparency.
How to Choose the Right PII Redaction Tool and Solution
When choosing a redaction software solution, it’s essential to consider features that align with your organization’s unique needs. Here are some must-have features to look for:
- Advanced AI and Machine Learning – Ensures precise identification and redaction of PII across multiple formats.
- Customizable Redaction Templates – Allows users to create templates suited to their specific regulatory requirements.
- Scalability – Supports large volumes of data for growing organizations.
- Integrated Audit Trail – Provides a log of all redactions, essential for compliance reporting.
- User-Friendly Interface – Simplifies onboarding and daily use for teams of all technical skill levels.
- Seamless Integration Capabilities – Connects with existing systems and workflows for a more cohesive experience.
Implementing PII Redaction Software
Introducing PII redaction software into an organization requires thoughtful planning. Here are some best practices to consider:
- Involve Key Stakeholders Early – Bring in Compliance Officers, IT Security Managers, and Legal Counsel from the beginning to ensure the software aligns with each department’s needs.
- Define Clear Redaction Standards – Establish redaction standards and templates to ensure team consistency.
- Set Up Audit Trails for Accountability – Implement processes for regularly generating and reviewing audit trails.
- Provide Training and Resources – Equip teams with adequate training to ensure they make the most of the software’s features.
- Regularly Review and Update Redaction Protocols – Periodically review your redaction protocols to ensure ongoing compliance and effectiveness.
By following these best practices, organizations can seamlessly integrate redaction software into their workflow, reducing risks and maximizing efficiency.
The Impact of Adopting PII Redaction Software
The decision to implement PII redaction software can transform the way organizations handle sensitive information. Here’s a closer look at the impacts:
- Enhanced Security and Privacy – Protecting PII with accurate, consistent redaction safeguards customer trust and corporate reputation.
- Regulatory Peace of Mind – With audit trails and automated compliance, organizations can confidently face regulatory scrutiny.
- Cost Savings – Reducing manual redaction tasks means fewer resources spent on labor, minimizing costs and maximizing productivity.
- Improved Customer Trust – Demonstrating a commitment to data security and privacy through redaction software reassures clients, strengthening relationships.
VIDIZMO’s AI-Powered PII Redaction Software for Law Enforcement and Enterprises
VIDIZMO Redactor offers an enterprise-grade Designed for law enforcement, government agencies, and enterprises, it ensures compliance with FOIA, CJIS, and other data privacy regulations while improving efficiency.
Key Features:
- AI-Powered Redaction – Accurately detects and redacts faces, license plates, screens, text, and spoken PII.
- Video & Audio Redaction – Supports bodycam, dashcam, interview room recordings, and surveillance footage for secure evidence handling.
- Document Redaction – Removes names, addresses, financial details, and other identifiers from scanned and digital documents.
- Customizable Redaction – Users can manually or automatically redact specific objects, words, or patterns.
- Compliance Assurance – Meets FOIA, CJIS, GDPR, HIPAA, and other regulatory standards.
- Scalable & Secure – Available for cloud, on-premises, or hybrid deployments with robust access controls.
VIDIZMO simplifies PII redaction with automation, accuracy, and compliance, reducing manual workload while protecting sensitive information.
How AI Identifies and Redacts Sensitive PII Data
AI-powered PII redaction software uses multiple detection technologies to accurately identify and redact sensitive data across different file formats.
For documents and scanned files, Optical Character Recognition (OCR) extracts text and automatically flags personally identifiable information such as names, addresses, social security numbers, and financial details for redaction.
In audio recordings, speech-to-text technology converts spoken content into searchable text, allowing the system to detect and redact sensitive PII from interviews, call recordings, and body-worn camera audio.
For video files, face and object detection algorithms automatically identify faces, license plates, screens, and other visual identifiers, enabling precise and consistent redaction without manual frame-by-frame review.
Final Thoughts: The Need for PII Redaction Software
Ensuring data privacy and regulatory compliance is no longer optional—it is a critical business requirement. A modern PII redaction solution enables organizations to automatically remove personally identifiable information from videos, audio recordings, and documents with accuracy and consistency.
Unlike manual processes, AI-powered PII redaction software reduces human error, accelerates redaction workflows, and helps law enforcement, government agencies, and enterprises meet strict regulations such as FOIA, CJIS, GDPR, and HIPAA.
See how an automated PII redaction tool can transform your compliance workflows. Request a demo or start your free trial today.

About the Author
Jump to
Best Bulk CCTV Video Redaction Tools for Enterprise and Government Use

Arizona Public Records Law: Transparency & Privacy with Redaction Tool


No Comments Yet
Let us know what you think