by Ali Rind, Last updated: June 11, 2026

FOI and public records request volumes have been climbing year over year across most jurisdictions. As public sector workloads exceed in-house capacity, consultancies absorb the overflow. Most of the visible attention in the FOI workflow goes to redaction, which is where the labor is most concentrated and the compliance risk is most visible. The silent bottleneck sits one step earlier.
Triage is the work that happens before a single line gets redacted. A consultant who spends three hours classifying a request, locating responsive records across systems, assessing scope, identifying third parties, and estimating effort is operating at a headcount-bound model. The redaction platform may be modern. The intake process is still manual review. AI changes the math at the front of the workflow as much as it does at the back.
This post covers what FOI triage actually involves, why manual triage stops scaling at portfolio size, where AI helps and where it does not, and how a triage layer can be added without replacing the FOI case management software the consultancy already runs.
What FOI Request Triage Actually Involves
The triage steps that happen before redaction starts:
Request intake and classification
The incoming request has to be sorted by type. A general request for records in the public interest. A personal information request from an individual asking for records about themselves. A repeat request from a frequent requester. A potentially vexatious request that warrants closer scrutiny. A request that touches third parties whose interests must be notified before disclosure. The classification drives the rest of the workflow.
Statute mapping
The applicable framework depends on the public body and the records. In the United States, federal records run under the Freedom of Information Act, and state public bodies operate under state-level public records laws. In Canada, Ontario municipal records run under MFIPPA, provincial records under FIPPA, federal records under the Access to Information Act, and health authority records under PHIPA on top of FIPPA. UK requests run under the Freedom of Information Act 2000. Each statute has its own exemption framework, response window, and appeal process.
Scope assessment and clarification
Many requests arrive with vague scope and require a clarification exchange with the requester before retrieval can start. Done well, this narrows the workload and reduces the chance of producing irrelevant records. Done poorly, the response covers the wrong material.
Locating responsive records
Records sit across email systems, document repositories, case management software, body-worn camera storage, 911 audio archives, and sometimes paper files. Locating the responsive set across these systems is its own project, and gaps here cause re-work later.
Identifying third parties who must be notified
Records that contain information about third parties (other individuals, businesses, partner agencies) typically require notification under FOI statutes before any release. The consultant has to identify these parties before processing.
Estimating effort and SLA risk
The consultancy needs an effort estimate to schedule resources and assess SLA risk against the statutory response window. A 200-page document response is a different commitment than a 40-hour body camera response.
Flagging politically sensitive or time-critical files
Records that touch executive personnel, ongoing litigation, or media-attention-likely topics need to be flagged for additional internal review before release.
Each step has to happen on every request. None of them is redaction.
Why Manual FOI Triage Does Not Scale Across a Multi-Client Portfolio
Triage relies on tribal knowledge of each client's record systems, exemption history, and stylistic norms. A senior consultant who has handled engagements with a specific public body for three years can triage a request from that client in 20 minutes. A new consultant doing the same work for the first time takes hours and is more likely to misclassify or miss a third party.
Ramping new consultants takes months. The institutional knowledge is in the heads of senior staff and only partially in process documentation. When the consultancy wins a new client, ramping the team to handle that client's records system, exemption preferences, and political sensitivities is a slow process that competes with billable hours.
Surge weeks compound the problem. When two or three clients have busy intake weeks at the same time, triage backlogs build. The redaction team sits waiting for triaged work while the consultants doing intake are over capacity. The bottleneck is invisible to anyone reading the redaction queue, but it pushes redaction deadlines backward by days.
Triage errors are more expensive than redaction errors because they cascade. A misclassified request type leads to wrong scope. Wrong scope leads to unnecessary records being processed and necessary records being missed. A missed third party leads to a release that should have been delayed for notification. The downstream rework costs more than the original triage step would have if it had been done correctly the first time.
Where AI Helps in FOI Request Triage
Request classification using natural language understanding
AI models trained on labeled FOI request examples can categorize incoming requests by type (general, personal, repeat, third-party-affected) with reasonable accuracy. The model surfaces a suggested classification that the consultant confirms or overrides. The classification step that took 30 minutes of senior consultant time becomes a five-minute review of an AI-suggested category.
Entity extraction across responsive records
Once responsive records are gathered, named-entity recognition extracts names, addresses, organizations, and dates across the set. The output is an inventory of who appears in the records, which feeds two downstream steps: redaction scope estimation and third-party identification. This is the same entity detection capability that powers PII redaction, applied earlier in the workflow for triage purposes.
Cross-record clustering for duplicates and near-duplicates
FOI requests for email correspondence often produce reply threads that contain near-duplicate content across many messages. Clustering algorithms group these by similarity, letting the consultant process them as a related set rather than redacting the same content many times. Pure duplicates can be surfaced for de-duplication before redaction.
Automated third-party identification
Surfacing names that appear in the records but are not the requester. The consultant reviews the surfaced list to determine which third parties require statutory notification before disclosure. AI handles the surfacing; the legal call on notification stays with the consultant.
Volume and effort estimation
Based on record count, file types (documents vs body camera footage vs 911 audio), and entity density, AI can produce an effort estimate that the consultancy uses for resource planning and SLA risk assessment. This replaces the senior consultant's gut estimate with a model-based estimate that improves over time as actual effort data feeds back into the model.
Sensitivity flagging based on content patterns
Records that reference active litigation, executive personnel, complaint procedures, or media-sensitive topics can be surfaced for additional review. AI flags candidates; the consultant decides whether each warrants escalation.
Where AI Should Not Be Used in FOI Triage
The honest counterweight. AI cannot apply the statutory framework to a specific record. It cannot decide what is exempt under a given exemption category. It cannot run the privacy balance test that weighs the requester's interest against the third party's. It cannot decide whether release is in the public interest. It cannot determine whether a record falls inside a solicitor-client or attorney-client privilege carve-out.
These are legal judgments that depend on context, precedent, and the specific facts of the record. AI is good at surfacing candidates for analysis. It is not good at the analysis itself.
Consultancies that try to automate the legal judgment step lose defensibility. Information commissioners and equivalent oversight bodies evaluate FOI responses based on the reasoned application of the statute, and a response produced by an AI model without consultant judgment cannot survive that scrutiny. Triage AI is a surfacing and classification layer, not a decision layer.
Connecting AI Triage and AI Redaction in a Single FOI Workflow
Triage AI and redaction AI are two ends of the same workflow. Triage AI scopes the request, surfaces the responsive records, identifies third parties, and estimates effort. Redaction AI processes the responsive records, detects PII and other sensitive content, and produces defensible release output.
The consultancy that runs both at scale handles substantially more portfolio with the same team. Triage time drops from hours per request to minutes. Redaction time drops because the scope and rules are pre-set from the triage output. Audit evidence accumulates across both stages, producing a release record that survives appeal.
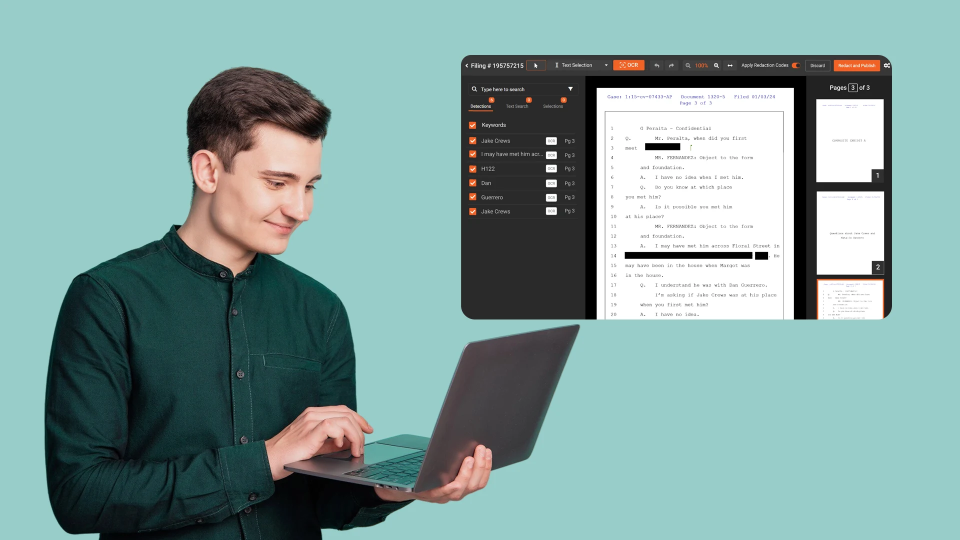
VIDIZMO Redactor handles the redaction stage with multi-format coverage (documents, video, audio, images), per-client workspace isolation, and regional data residency for dedicated SaaS deployments. For more on the redaction stage at portfolio scale, see scaling redaction across multiple public sector clients. The redaction platform integrates with FOI case management and triage layers via REST API and webhook events. For the broader product context, see FOIA public records redaction software, government agencies, AI-powered document redaction software, video redaction software, and audio redaction software.
Book a demo to see how the redaction stage fits into a consultancy workflow with triage AI upstream.

About the Author

Jump to

Public Safety Transparency vs. Privacy: FOIL and Data Protection
How Redaction Software Protects Sensitive Data Before Public Release


No Comments Yet
Let us know what you think