by Ali Rind, Last updated: July 15, 2026
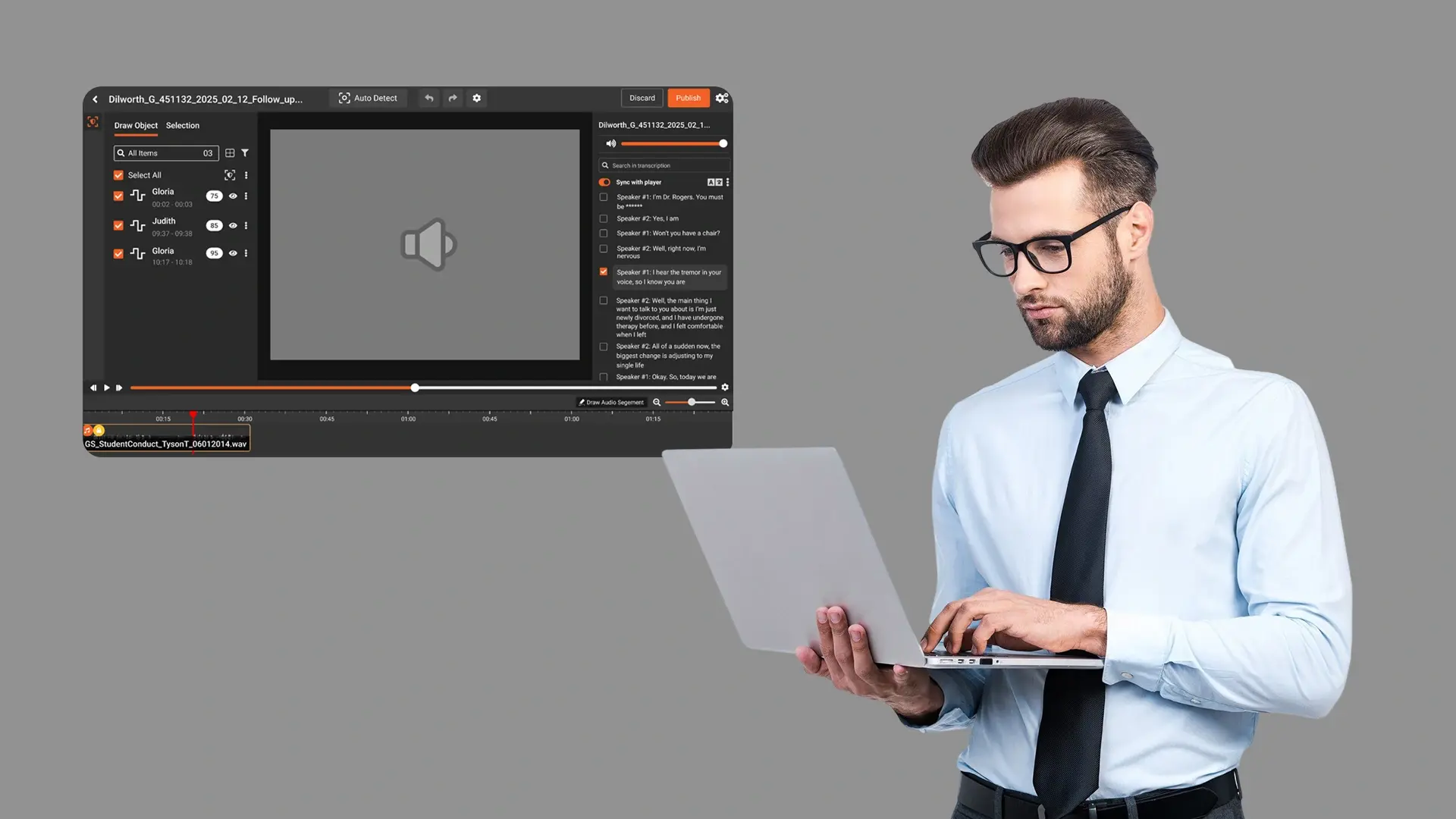
TL;DR. A multi-year unredacted call recording archive is a live compliance problem under PCI DSS, GDPR, and CCPA. Clearing it is a distinct project from ongoing call redaction. This guide walks through scoping, sampling, deployment choice, scaled processing, QA, and delivery, so the backlog gets cleared once and stays cleared.
Most enterprises with a contact center history have one. A stored archive of call recordings stretching back years, untouched since the day it was recorded, sitting in cold storage or a legacy telephony platform. The recordings were useful when they were captured. They are now a liability.
Clearing a historical backlog is a different project than ongoing redaction. Ongoing redaction is about applying policy to new recordings as they come in. A backlog is a one-time workload at a scale most teams have never planned for, with compliance pressure that grows as new privacy regulations take effect. This guide walks through how to treat it as its own project.
The Hidden Risk Sitting in Stored Call Recordings
Most contact centers record calls by default. Quality assurance, training, dispute resolution, regulatory readiness. The recordings pile up. Over a decade of operations, a mid-sized contact center can accumulate millions of hours of audio. A large enterprise can reach tens of millions.
What sits in those recordings is almost always in scope of some regulation. Credit card numbers read aloud during a payment, Social Security numbers given during identity verification, medical information shared with a benefits agent, addresses, dates of birth, account numbers, passwords. In industries like healthcare, insurance, and financial services, every call in the archive likely contains at least one category of protected data. Automated audio redaction is the only sustainable way to address archives at this scale, because manual review of thousands of hours is neither accurate nor economical.
The risk is cumulative. A single recording is a small exposure. A ten-year archive with no redaction is an audit finding waiting to happen, a breach multiplier if the archive is ever accessed, and a legal liability when a DSAR or discovery request asks for recordings from a specific individual.
When a Backlog Becomes a Compliance Problem
Three regulatory triggers push organizations from "we'll get to it" to "we need a plan now."
PCI DSS. Storage of cardholder data after authorization is prohibited by PCI DSS Requirement 3.2. Spoken card numbers captured in call recordings fall under the same rule. Enterprises that retain unredacted calls containing card data are carrying a compliance gap that any PCI assessment will surface. The PCI Security Standards Council has been clear that voice recordings are in scope when they contain card data. For a deeper look at how the standard maps to stored audio, see our guide on PCI DSS compliance software for cardholder data redaction.
GDPR and UK GDPR. Article 5 requires data minimization and purpose limitation. A ten-year archive of raw recordings almost never passes a purpose limitation review. Article 17's right to erasure means that when a data subject requests deletion of their personal data, you need to be able to locate and act on their recordings, which is impractical with an unprocessed archive.
CCPA and CPRA. California residents have the right to know what personal information is held about them and the right to delete it. The right applies to voice recordings. An enterprise with operations touching California residents needs to be able to retrieve or delete by individual, which starts with knowing what is in the archive.
NIST SP 800-53. Federal and federal-adjacent organizations operate under NIST SP 800-53 retention and minimization controls that apply directly to recorded audio containing regulated data.
Any one of these is enough to elevate a backlog from background concern to active project.
Phase 1: Scoping
The first phase is not technical. It is inventory work that determines the size and shape of the project.
Start with volume. Total hours of audio, broken out by year, by business unit, by campaign or line of business if the data allows. Distinguish between recordings still in active retention and recordings past any legitimate business need. The second category often accounts for the majority of the archive and may be eligible for deletion rather than redaction, which changes the economics of the project immediately.
Next, language coverage. A multinational enterprise rarely has a single-language archive. Even US-centric contact centers often have Spanish-language recordings mixed in. Non-English recordings cannot be treated as a long tail; they need their own handling plan because transcription and PII detection models operate differently per language. Our guide on redacting PII in non-English call recordings covers the specifics for Spanish, Portuguese, CJK, and other language families.
Then, PII and PCI scope. List the data categories your regulatory framework requires you to redact. For a financial services firm, that typically includes credit card numbers, CVVs, bank account numbers, Social Security numbers, dates of birth, full names, addresses, phone numbers, and passwords. For healthcare, add medical record numbers, diagnosis information, and treatment details. For general commercial operations, the list is shorter but still substantial. Platforms built for this work detect across dozens of categories out of the box, which matters when the archive spans multiple business units with different sensitivity profiles. See the full list on the spoken PII redaction feature page.
Finally, retention policy. If current policy is unwritten or inconsistent, codify it before starting redaction. The policy determines which recordings are redacted and retained versus redacted and deleted versus simply deleted. Running redaction on recordings that should be deleted is wasted work.
Phase 2: Sampling Before Full-Scale Redaction
Do not commit to a full-archive redaction run without a sampling phase. Sampling surfaces the operational realities that scoping cannot.
Pull a representative sample across years, business units, and languages. Two hundred to five hundred recordings is usually enough for a statistically useful first pass. Run the full redaction pipeline end to end: transcription, PII and PCI detection, redaction, output generation, and audit logging.
Measure three things. First, detection accuracy. How often is PII being caught? How often is something flagged that is not actually PII (false positives)? How often is real PII missed (false negatives)? Second, throughput. How long does a recording take, end to end, from ingest to output? This number multiplied by total volume gives a realistic project timeline. Third, cost. Processing cost per hour of audio, scaled to full archive size, sets the budget envelope.
Sampling also tells you which recordings cannot be processed without intervention. Corrupted files, unsupported codecs, extremely poor audio quality. These are edge cases that need a separate workflow, and you want to discover them on 500 recordings rather than 5 million. A broader walkthrough of the workflow from ingest to output lives in our audio redaction services guide.
Phase 3: Choosing Deployment
Archive redaction puts pressure on deployment choice in ways ongoing redaction does not. The volume is concentrated. The data is often sensitive. The processing window is typically finite.
SaaS. Vendor-hosted multi-tenant SaaS is the lowest-friction option. No infrastructure work, fast provisioning, consumption-based pricing. It is the right choice when the archive is not classified or restricted, when the business is comfortable with cloud processing, and when the volume is under approximately 1 million hours. At larger volumes, the economics sometimes tilt toward a dedicated or private cloud model.
Dedicated SaaS or private cloud. Single-tenant infrastructure, either vendor-hosted or in the customer's own Azure, AWS, or GCP environment. This is the model for enterprises with data residency requirements, for regulated industries where multi-tenant processing is a non-starter, and for very large archives where dedicated capacity is more cost-predictable than per-unit consumption. VIDIZMO supports deployment in Azure Government for organizations with CJIS or federal data handling requirements.
On-premises. Customer-installed, customer-managed. The right choice when the archive contains classified material, when air-gapped operation is required, or when the data cannot leave existing infrastructure for contractual or regulatory reasons. On-premises deployment requires more upfront investment but removes data transit as a variable.
Hybrid. On-premises processing for the sensitive portion of the archive, cloud processing for the rest. Useful when only part of the archive is restricted and the remainder can be processed more economically in SaaS.
VIDIZMO Redactor supports all four. The deployment choice for the backlog project does not have to match the deployment choice for ongoing redaction; many enterprises run a dedicated backlog project separately from their standing redaction platform.
Phase 4: Running Redaction at Scale
With deployment chosen, execution becomes a throughput problem. The tooling needs to process the archive without manual intervention per file.
Bulk redaction workflows handle this. Submit files in batches, let the platform queue and process them, receive outputs with associated audit records. VIDIZMO Redactor's bulk processing has been tested against 1.1 million recordings in deployment, and the platform runs continuously during off-hours or in dedicated processing windows.
Key operational decisions during execution:
Speaker diarization. Multi-party call recordings benefit from speaker-level separation. When only the customer needs to be redacted and the agent does not, diarization allows selective redaction rather than blanket muting. It also improves detection accuracy because each speaker's audio is processed in a cleaner stream.
Confidence threshold tuning. The platform exposes confidence thresholds for PII detection. Tuning them is a trade-off between catching more items (lower threshold) and reducing false positives (higher threshold). Archive projects usually run at lower thresholds with human QA review on flagged items, because missing PII in an archive is worse than reviewing extra items.
Resumability. Batch jobs fail. Network interrupts, storage outages, scheduler glitches. The platform should support resumption from where it stopped rather than restart from the beginning. Without this, a 5-million-hour project becomes impossible to complete inside a reasonable window.
Output format. Decide upfront whether redaction is destructive (the sensitive content is permanently removed) or preserves an audit copy. For compliance purposes, most enterprises retain the original in a secure vault and deliver only redacted copies downstream.
For a contact-center specific view of these workflows, see redaction software for call centers. For reference scale, a major California county used VIDIZMO Redactor to process 1.1 million call recordings in health services for CCPA compliance, deploying within their own cloud environment.
Phase 5: QA, Chain of Custody, and Delivery
The final phase is where archive projects most often fall short. Redaction is only defensible if it can be audited, and an archive project delivers value only when the redacted output actually reaches the systems and stakeholders that need it.
Quality assurance. Run a statistical sample of the redacted output back through review. A 1 to 3 percent sample, stratified across languages, business units, and time periods, catches systematic detection failures before they become audit findings. Where possible, route flagged segments (low-confidence detections) to human reviewers in a structured queue rather than trusting automated output alone. This human-in-the-loop layer is what separates a defensible archive project from one that creates new risk.
Chain of custody. Every action on every file needs to be logged. Who ingested it, when redaction ran, which rules applied, what was detected, what was redacted, who reviewed, when the redacted copy was delivered, who received it. The log needs to be immutable and exportable, because regulators and counsel will ask for it. Redactor produces this audit trail automatically as part of the processing pipeline, which is a baseline requirement for any enterprise archive project.
Retention of originals. Decide the retention policy for pre-redaction originals before redaction starts. In most cases the answer is: retain originals in a locked, access-restricted vault for a fixed window (often 30 to 90 days) to allow for re-processing if a rule needs to change, then destroy per policy. Destroying originals immediately removes the safety net; retaining them indefinitely recreates the original compliance problem.
Delivery. Redacted recordings are rarely useful in a generic dump. They need to be delivered back into the systems that will use them: quality management platforms, analytics tools, legal hold repositories, training data stores. Map the downstream systems during scoping, not delivery, so the output format and metadata match what each consumer expects.
Common Pitfalls on Archive Projects
A few patterns recur across projects and are worth flagging explicitly.
Skipping the scoping phase. Teams that go straight from "we have a backlog" to "start processing" end up processing recordings that should have been deleted, missing language coverage gaps, and discovering edge-case formats mid-run. The scoping phase feels slow but compresses total project time.
Treating the backlog as an ongoing project. A backlog has a defined start and end. An ongoing redaction program does not. Running the two the same way leads to either under-resourcing (the backlog never finishes) or over-resourcing (ongoing costs balloon after the backlog clears).
Underestimating QA effort. Detection accuracy is not 100 percent and never will be. Budget explicit QA time and headcount as part of the project plan, not as an afterthought. On a million-hour archive, even a 1 percent QA sample is ten thousand hours of review.
Overlooking non-English audio. A 5 percent Spanish subset of a million-hour archive is 50,000 hours. That is a project in its own right. Handle it with the same rigor, not as a rounding error.
Ignoring the delivery step. Redacted files that never make it back into production systems add cost without reducing risk. Plan delivery workflows during scoping.
For enterprises where internal bandwidth is the bottleneck rather than tooling, VIDIZMO's white glove redaction services deliver the same platform with a managed team handling configuration, QA, and delivery.
Ready to clear a call recording backlog?
Request a redaction assessment and we will walk through scoping, sampling, and deployment for your archive.

Frequently Asked Questions
Timelines depend on deployment, concurrency, and QA depth, not a single throughput number. A million-hour archive running on a dedicated cloud deployment with parallel processing typically completes in weeks to a few months, including QA. On-premises deployments vary with hardware capacity. The most reliable timeline estimate comes from running a 500-recording sample and extrapolating, which is why the sampling phase matters.
Backlog redaction is a one-time project with a finite scope, concentrated volume, and a defined end. Ongoing redaction applies policy to new recordings as they arrive and runs continuously. The two have different deployment, throughput, and pricing profiles, which is why many enterprises treat them as separate projects even when using the same platform.
In most cases, retaining originals for a defined window (typically 30 to 90 days post-redaction) is good practice, in a locked and access-controlled vault, in case detection rules need to be updated and recordings re-processed. After the window, originals should be destroyed per retention policy. Retaining them indefinitely recreates the original compliance exposure.
Configure detection rules to cover all applicable categories (PII, PCI, PHI as needed) in a single pass. Running separate passes per category adds processing time and complicates audit trails. Most enterprises run a unified rule set with all required categories enabled, then tune confidence thresholds per category based on the QA results from the sampling phase.
Failed recordings should route to an exception queue rather than being silently skipped. Common causes are corrupted files, unsupported codecs, or audio quality too poor for reliable transcription. The exception queue is handled separately: some files are reprocessed after cleanup, some are manually reviewed, some are destroyed if their compliance value is lower than the cost of processing. Logging the exception handling decision is part of chain of custody.
Speaker diarization separates the audio streams of different speakers in a recording. For a two-party call, this allows the platform to process the customer's audio and the agent's audio independently, which typically improves PII detection accuracy because each stream is cleaner. It also enables selective redaction, such as redacting customer-spoken PII while leaving agent audio untouched for training purposes.
No. On-premises is required when the data cannot leave existing infrastructure for contractual or classification reasons. For most commercial archives, a dedicated cloud or private cloud deployment provides equivalent security with faster time to value. The deployment decision should follow from the data classification and regulatory requirements, not from a default preference.
About the Author

Jump to
How to Redact PCI Data: Credit Card and Bank Account Numbers

How BPO Companies Handle Client PII Compliance with AI Redaction

No Comments Yet
Let us know what you think