by Hassaan Mazhar, Last updated: June 8, 2026
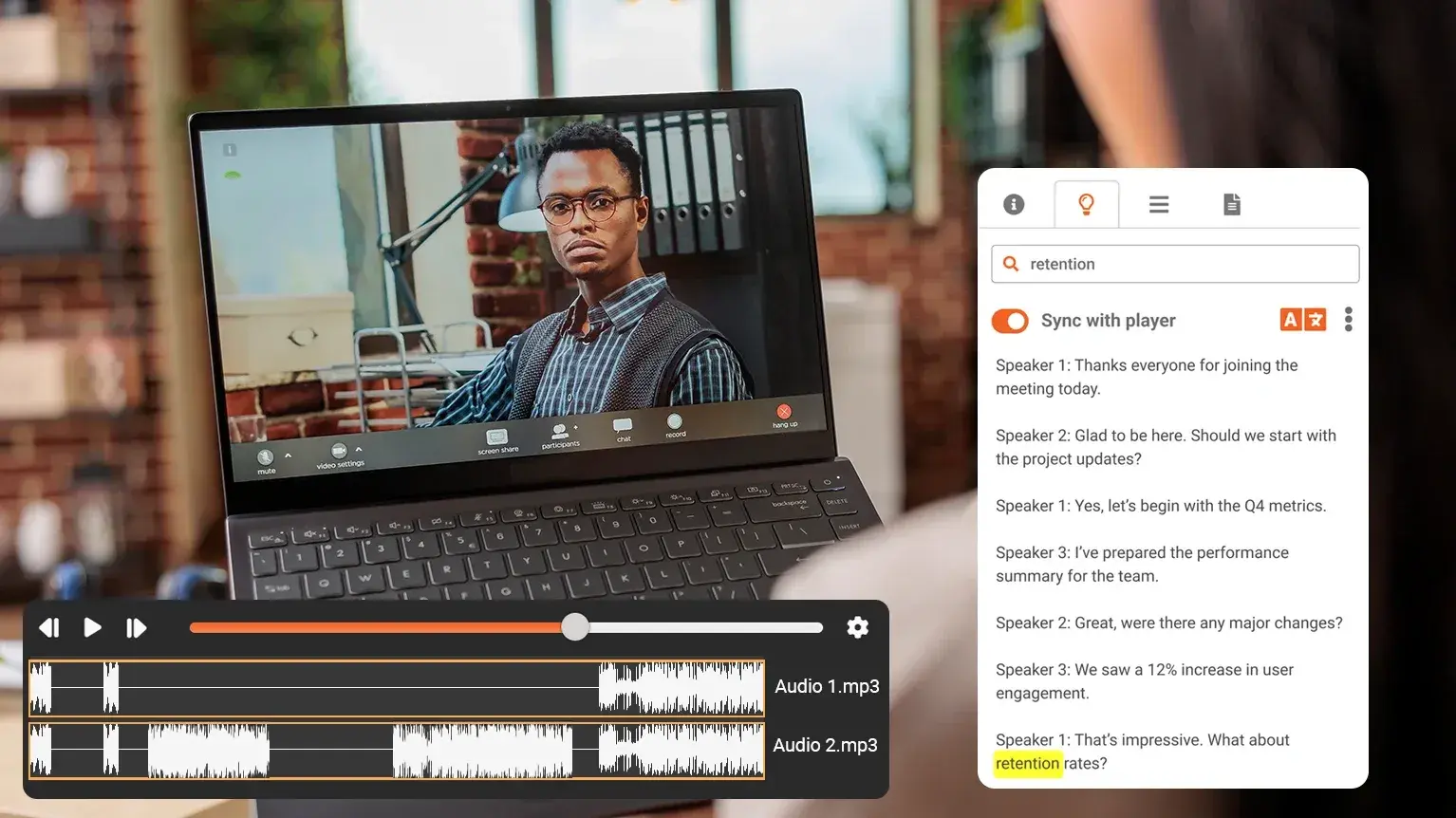
When a recorded meeting, training session, or compliance call contains five people talking over each other, a transcript that reads "Speaker 1... Speaker 2... Speaker 1..." is nearly useless. You need to know *who* said what, by name, by role, with a timestamp you can defend in an audit or a courtroom.
That is what speaker diarization solves. And for organizations in regulated industries, healthcare, financial services, legal, government, it is quickly moving from a nice-to-have to an operational requirement.
The global speaker diarization service market reached USD 1.21 billion in 2024 and is projected to grow at a CAGR of 16.8% through 2033, driven largely by compliance mandates in these industries.
This blog takes you through the concept of Speaker Diarization and the increasing need to adopt this before you find yourself in bottlenecks that can adversely affect your operational efficiency.
What Is Speaker Diarization?
Speaker diarization is the process of automatically segmenting an audio or video recording by speaker, determining "who spoke when" across the entire timeline. The output is a transcript where each spoken segment is labeled with a distinct speaker identity.
A basic diarization output looks like this:
[00:02:14] Dr. Martinez: The patient was admitted with elevated markers...
[00:02:41] Nurse Chen: I documented the intake at 10:15 AM...
The AI does not know these names initially. It detects distinct voice patterns, pitch, cadence, tone, and groups them into clusters. Your platform then maps those clusters to known speaker profiles or lets administrators label them post-call.
In a modern enterprise video platform, diarization runs automatically during transcription processing. You upload or ingest the video, and the system returns a structured, speaker-labeled transcript without manual effort.
Why Regulated Industries Need Speaker Attribution, Not Just Transcripts
Generic transcription gives you words. Speaker diarization gives you accountability.
In regulated contexts, accountability is everything.
Healthcare
A clinical consultation recording where the clinician's questions are mixed with the patient's responses creates liability if the two voices are not separated. HIPAA-compliant documentation requires clarity about who communicated what during a care encounter. Medical boards and malpractice proceedings depend on it.
Financial Services
Financial trading floor communications and client advisory calls fall under MiFID II, SEC Rule 17a-4, and FINRA recordkeeping requirements. Verint research on financial compliance diarization notes that "who said what when" is a live compliance challenge for financial firms archiving call data. Some firms now require diarization as a formal part of call archival policies.
Legal and Government
Depositions, administrative hearings, and government proceedings require speaker attribution that carries legal weight. Misattributing a statement, even by accident, can undermine evidence. Diarized transcripts become auditable records with provable speaker chains.
How Speaker Diarization Works in an Enterprise Video Platform
Understanding the mechanics helps you evaluate platforms intelligently.
-
Step 1: Voice Activity Detection
The system scans the audio track and identifies segments where speech is present versus silence, background noise, or music.
-
Step 2: Speaker Embedding
Each speech segment is converted into a numerical "voice fingerprint" (embedding) that captures the acoustic characteristics of that speaker. Modern neural models, including transformer-based architectures, power this step.
-
Step 3: Clustering
The system groups embeddings that sound similar. If the same voice appears across 40 segments throughout a 90-minute recording, all 40 get clustered together as one speaker.
-
Step 4: Labeling
The clusters are assigned placeholder labels (Speaker A, Speaker B). In enterprise platforms, administrators or authorized users can then relabel these with actual names from a directory, or the platform can auto-match against stored voiceprints if speaker enrollment is configured.
The Real Pain Points Diarization Solves
Before evaluating features, it helps to name the problems you are actually trying to solve.
-
Problem 1: Post-meeting review takes too long.
When a three-hour board meeting produces an unlabeled transcript, finding who approved a specific action item requires reading everything. Diarized transcripts let you filter by speaker and jump directly to their segments.
-
Problem 2: Compliance teams cannot attribute statements.
An audit of a customer advisory call is meaningless if you cannot distinguish the advisor's disclosures from the client's acknowledgments.
-
Problem 3: Training content accountability breaks down.
In compliance training recorded as a live session with Q&A, HR and L&D teams need to know which employees asked questions and what answers they received, especially for certification purposes.
-
Problem 4: Accessibility requirements apply per speaker.
Section 508 and ADA compliance for video content requires accurate captions. Captions that mix speakers without labels are harder to follow for viewers with hearing impairments.
What to Look for in Enterprise-Grade Speaker Diarization
Not all implementations are equal. Evaluate platforms on these criteria.
Accuracy Across Speaker Counts
Two-speaker recordings are easy. Enterprise meetings often have eight to fifteen participants. Look for platforms tested on high speaker-count recordings with published accuracy benchmarks.
Language Support
A global organization running training in Spanish, Mandarin, and Arabic needs diarization that works across languages, not just English. VIDIZMO EnterpriseTube supports automatic transcription in 82 languages, with speaker diarization applied across that same language set.
Integration with Your Identity Infrastructure
The most useful diarization connects speaker labels to your directory, Azure AD, Okta, or any SAML 2.0 provider. When Speaker A is automatically resolved to "Jim Halpert, Regional Compliance Lead," the transcript becomes immediately actionable.
Compliance-Ready Storage and Access Control
Speaker-labeled transcripts contain sensitive information about individuals. Your platform must enforce the same access controls on transcripts as on the video itself, role-based access control (RBAC), audit logging, and encryption at rest (AES-256) and in transit (TLS 1.3).
Deployment Flexibility
Healthcare organizations and financial services firms often cannot send audio data to a public cloud for processing. On-premises or private cloud deployment of the diarization pipeline is a hard requirement, not a preference.
How VIDIZMO EnterpriseTube Handles Speaker Diarization
VIDIZMO EnterpriseTube includes speaker diarization as part of its AI-powered processing layer. When a video is uploaded or ingested from Microsoft Teams, Zoom, Webex, or any connected conferencing system, the platform automatically:
-
Detects and separates individual speaker voices
-
Generates a structured, speaker-labeled transcript
-
Aligns the transcript to video playback for synchronized review
-
Makes transcript content searchable, search by speaker, keyword, or timestamp
-
Applies the same RBAC permissions governing the video to its transcript
Authorized users can edit speaker labels to map them to real names. Those corrections persist across the platform and apply retroactively through the transcript record.
This integrates with EnterpriseTube's automatic transcription feature, which supports 82 languages and produces accessible, Section 508–compliant captions from the same processing pipeline.
For organizations managing video from remote or hybrid work environments, the speaker diarization capability addresses the core challenge outlined in enterprise video streaming for distributed teams, turning raw recordings into searchable, attributed records.
EnterpriseTube deploys as SaaS, dedicated cloud, on-premises, or hybrid, giving regulated industries the processing control they require. For organizations comparing video training platforms with built-in AI capabilities, see our overview of enterprise video content management for training.
Conclusion
Speaker diarization is not a transcription add-on. In regulated industries, it is the mechanism that turns a recording into an auditable, attributable record.
If your organization is evaluating enterprise video platforms, ask vendors specifically how they handle speaker diarization, how it scales to large speaker counts, whether it integrates with your identity provider, and whether the underlying processing can stay within your network boundary.
VIDIZMO EnterpriseTube handles all of this as part of a single, compliance-ready video management platform.
See how EnterpriseTube manages speaker identification across your video library

About the Author
Jump to

How AI-Based Speech-to-Text Improves Audio Evidence Analysis
.webp)
Top Enterprise AI Video Search Platforms Compared (2026)


No Comments Yet
Let us know what you think