by Ali Rind, Last updated: May 19, 2026
In September 2025, Judge Victoria Kolakowski of Alameda County Superior Court watched a video exhibit submitted as a witness statement and noticed the witness's face barely moved. The voice was disjointed. The mannerisms repeated. The court eventually identified it as one of the first AI-generated deepfakes submitted as authentic evidence in a U.S. case, and dismissed Mendones v. Cushman & Wakefield over it.
The case is talked about as a deepfake story. It is also, quietly, a multi-modal evidence story. The judge had to evaluate video, audio, and the documents that came with the exhibit, together. A modern litigation matter routinely requires that same kind of cross-modal analysis. The case record has not been document-only for some time.
Most of the legal AI tools attorneys evaluate in 2026 are. That is the gap this post is about.
What the modern legal case record actually contains in 2026
Walk into a complex matter today and the file looks nothing like the file from ten years ago. Personal injury cases include medical records, billing summaries, deposition transcripts, and the videos of those depositions, interview recordings, hospital surveillance footage, and dashcam clips from the accident.
Employment cases now routinely include Slack and Teams exports, recorded all-hands meetings, voicemails, and HR interview recordings. Criminal defense files contain body cam footage, jail call audio, surveillance video, scanned police reports, and digital extractions from phones. Family law has voicemails, text screenshots, and increasingly, recordings submitted as proof of threats or violations.
None of this is unusual anymore. Surveillance footage, deposition recordings, drone footage, dashcam video, and body camera content are standard evidence types in commercial litigation, criminal defense, employment disputes, and internal investigations. The volume is going up, not down. For a deeper look at how this changes e-discovery specifically, see our guide on video evidence in e-discovery.
The point is not that documents are obsolete. They still anchor the record. The point is that the documents alone no longer tell the story, and a tool that only reads documents only sees part of the case.
Harvey, Spellbook, and CoCounsel: what these legal AI tools actually do
The category framing is the whole question here. Harvey's litigation product line is built around analyzing complaints, discovery, expert reports, and deposition transcripts. Harvey's own litigation product page describes deposition workflows that synthesize and summarize transcripts to generate cross-examination questions. The transcript is the input, not the video.
Spellbook is a Microsoft Word side-panel for contract drafting and redlining. Excellent at what it does. It does not handle audio or video at all.
CoCounsel, now part of Thomson Reuters, focuses on legal research, document comparison, timeline generation, and database integration. Categorized in industry roundups as restricted to textual content and specific database connections.
None of this is a weakness. These are accurate category descriptions. The tools were built for the part of the case that lives in text, and they are strong inside that boundary. The question for a lawyer evaluating them in 2026 is whether the part of the case that lives outside that boundary is small enough to ignore.
For most modern litigation, the answer is no.
5 legal AI workflows where document-only tools fall short
Concrete examples are more useful than abstractions. Here are five places the gap is operational, not theoretical.
Comparing the video deposition to the transcript
A witness says something on camera that the certified transcript does not capture cleanly, or a pause, hesitation, or off-record comment changes the meaning of the testimony. A document-only tool reads the transcript and stops. The video stays unindexed unless someone watches it.
Cross-referencing recorded client interview with the signed statement
The interview was recorded. The statement was typed up from it. Are they consistent? A modern multimodal AI compares the audio against the document automatically. A document-only AI can only read the statement.
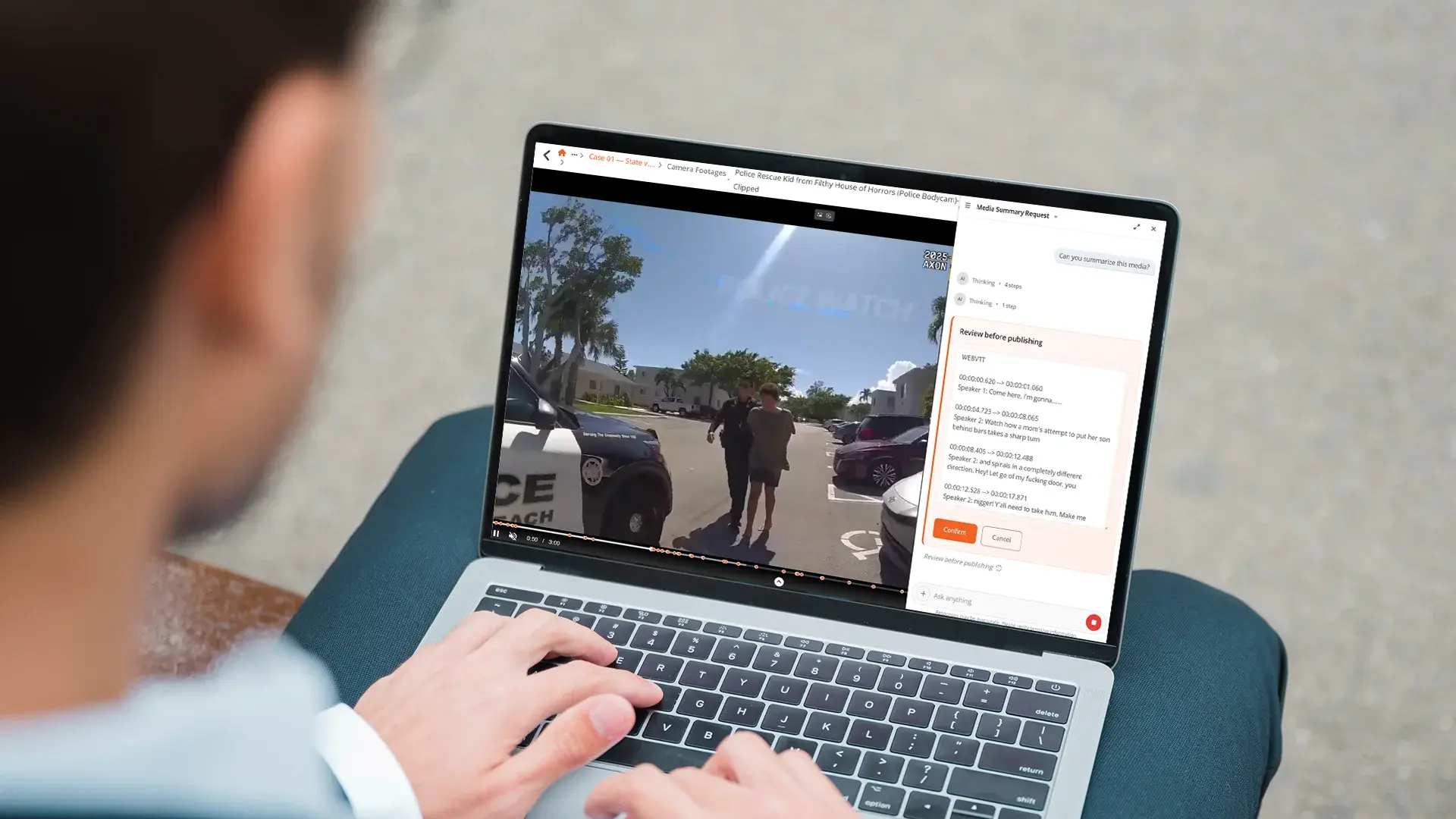
Finding the moment in body cam footage that matches a witness account
A defense attorney has a four-hour body cam clip and a written witness statement claiming the officer issued a verbal warning at a specific point. Locating that moment manually means scrubbing through the video. With AI that can search across transcripts, detected objects, and audio together, it takes a single query. We covered the mechanics of this workflow in more detail in the AI chatbot for video evidence search post.
Reading scanned handwritten physician notes alongside structured EHR data
Medical malpractice and Social Security disability work both depend on this. The structured chart says one thing. The handwritten note in the margin says another. Document-only AI either misses the handwritten content or reads it without context. Multi-modal AI processes both as part of the same record.
Building a timeline that spans documents and recorded evidence
Reconstructing what happened on a given day usually means pulling timestamps from emails, photos, surveillance footage, body cam clips, and witness statements together. A document-only tool produces the document portion of the timeline. The full picture requires a tool that reads the rest.
In each of these, the answers the document-only AI gives are accurate as far as they go. They just leave large parts of the record untouched.
What multi-modal legal AI requires: 5 core capabilities
The phrase gets used loosely. A tool that can transcribe audio is not the same as a tool that can analyze it alongside the rest of the case record. A useful working definition has five components:
- Search inside video, not just video metadata. Knowing a file is named "interview_03.mp4" does not help. Knowing the speaker said "I never agreed to that" at 00:42:11 does.
- Speaker-separated audio analysis. Most legal audio has two or more voices, and the question of who said what is usually the whole point.
- OCR for handwritten and scanned content. A significant share of legal records still arrives this way, especially medical files, court exhibits, and older case material.
- Image and frame-level recognition. Faces, vehicles, license plates, weapons, and other objects relevant to the matter, identified and timestamped automatically.
- Source citation to the exact timestamp, page, or frame. Every answer ties back to a specific second of video, page of a document, or frame of an image. The reviewer can verify in one click instead of reading 40 pages of source material.
The last one matters more than it used to. After 2025's wave of court sanctions for hallucinated citations in legal filings, every credible legal AI platform now claims to ground its answers. The question is what the grounding actually points to. Citing a paragraph in a document is the standard. Citing a specific second of a video, with the clip viewable from the answer, is the multi-modal equivalent.
Do you need multi-modal legal AI, or is document-only enough?
Document-only AI is succeeding at the slice of the work it was built for. The catch is that the slice keeps shrinking as a percentage of what a modern matter actually contains. Lawyers evaluating AI in 2026 should know what their tool covers and what it will leave unindexed.
If your firm is staying with enterprise SaaS for the document work and wants the rest of the case record covered too, request a demo of VIDIZMO Intelligence Hub to see how multi-modal analysis works on a real matter from your practice.

About the Author

Jump to

How AI Chatbots Are Changing the Way Officers Review Footage

How Litigation Teams Handle Evidence Analysis Across Every Format


No Comments Yet
Let us know what you think